library(rvest)
library(xml2)
library(tidyverse)Starbucks
Web scraping
O processo de web scraping consiste em extrair informação de uma página na internet. A dificuldade ou facilidade em extrair esta informação depende da qualidade de construção da página. Em alguns casos mais complexos, a informação pode estar atrás de um captcha ou num painel interativo que depende de outros comandos do usuário.
Neste exemplo simples vou mostrar como conseguir encontrar a localização de todas as unidades da Starbucks no Brasil. A lista completa das lojas em atividade da Starbucks pode ser encontrada no site do Starbucks Brasil. Como de praxe, vamos utilizar o tidyverse em conjunto com os pacotes rvest e xml2.
O site
A lista completa das lojas em atividade da Starbucks pode ser encontrada no site do Starbucks Brasil. Para ler a página usa-se read_html.
url = "https://starbucks.com.br/lojas"
page = xml2::read_html(url)O “xpath” mostra o caminho até um determinado elemento na página. Para encontrar o logo do Starbucks, no canto superior-esquerdo da página, por exemplo podemos usar o código abaixo.
page %>%
html_element(xpath = "/html/body/div[1]/div[1]/header/nav/div/div[1]/a/img"){html_node}
<img alt="Starbucks Logo" src="/public/img/icons/starbucks-nav-logo.svg">Para ver mais sobre xpaths consulte este cheatsheet.
Em geral, em páginas bem construídas, o nome dos elementos será bastante auto-explicativo. No caso acima, o atributo “alt” já indica que é objeto é o logo da starbucks e o “src” direciona para um arquivo em formato svg (imagem) chamado starbucks-nav-logo. Infelizmente, isto nem sempre será o caso. Em algumas páginas os elementos podem ser bastante confusos.
Para puxar um atributo específico usamos a função html_attr.
page %>%
html_element(
xpath = "/html/body/div[1]/div[1]/header/nav/div/div[1]/a/img"
) %>%
html_attr("src")[1] "/public/img/icons/starbucks-nav-logo.svg"Se você combinar este último link a “www.starbucks.com.br” você deve chegar numa imagem com o logo da empresa1.
![]()
Para encontrar a grande lista de lojas no painel da esquerda vamos aproveitar o fato de que o div que guarda esta lista tem uma classe única chamada “place-list”. É fácil verificar isto no próprio navegador. Se você usar o Chrome, por exemplo, basta clicar com o botão direito sobre o painel e clicar em Inspect.

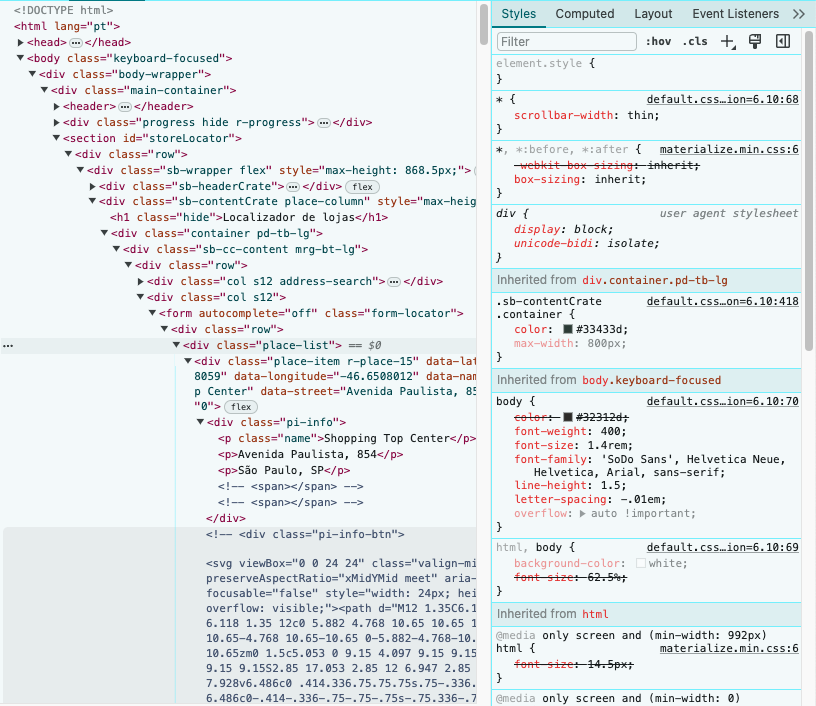
Como comentei acima, nem sempre as coisas estarão bem organizadas. Note que como queremos puxar múltiplos elementos e múltiplos (todos) os atributos usamamos as variantes: html_elements e html_attrs.
list_attr <- page %>%
html_elements(xpath = '//div[@class="place-list"]/div') %>%
html_attrs()O objeto extraído é uma lista onde cada elemento é um vetor de texto que contém as seguintes informações. Temos o nome da loja, a latitude/longitude, e o endereço.
pluck(list_attr, 1) class data-latitude data-longitude
"place-item r-place-15" "-23.5658059" "-46.6508012"
data-name data-street data-index
"Shopping Top Center" "Avenida Paulista, 854" "0" A esta altura, o processo de webscrapping já terminou. Novamente, o processo foi fácil, pois os dados estão muito bem estruturados na página da Starbucks. Agora, precisamos apenas limpar os dados.
Limpeza de dados
Não vou me alongar muito nos detalhes. Basicamente precisamos converter cada elemento da lista em um data.frame, empilhar os resultados e aí converter os tipos de cada coluna.
# Convert os elementos em data.frame
dat <- map(list_attr, \(x) as.data.frame(t(x)))
# Empilha os resultados
dat <- bind_rows(dat)
clean_dat <- dat %>%
as_tibble() %>%
# Renomeia as colunas
rename_with(~str_remove(.x, "data-")) %>%
rename(lat = latitude, lng = longitude) %>%
# Seleciona as colunas de interesse
select(index, name, street, lat, lng) %>%
# Convert lat/lng para numérico
mutate(
lat = as.numeric(lat),
lng = as.numeric(lng),
index = as.numeric(index),
name = str_trim(name)
)
clean_dat# A tibble: 110 × 5
index name street lat
<dbl> <chr> <chr> <dbl>
1 0 Shopping Top Center Avenida Paulista, 854 -23.6
2 1 Paulista 500 Avenida Paulista, 500 -23.6
3 2 Shopping Cidade São Paulo Avenida Paulista, 1154 -23.6
4 3 Shopping Patio Paulista Rua Treze de Maio, 1933 -23.6
5 4 Eliseu Guilherme Rua Desembargador Eliseu Guilherme, 200 -23.6
6 5 Shopping Center 3 Avenida Paulista, 2064 -23.6
7 6 Shopping Frei Caneca Rua Frei Caneca, 569 -23.6
8 7 Haddock Lobo Rua Haddock Lobo, 608 -23.6
9 8 Mackenzie Rua Maria Antônia, 293 - 403 -23.5
10 9 Shopping Higienopolis Avenida Higienópolis, 618 -23.5
lng
<dbl>
1 -46.7
2 -46.6
3 -46.7
4 -46.6
5 -46.6
6 -46.7
7 -46.7
8 -46.7
9 -46.7
10 -46.7
# ℹ 100 more rowsMapa
A tabela acima já está em um formato bastante satisfatório. Podemos verificar os dados construindo um mapa simples.
library(sf)
library(leaflet)
starbucks <- st_as_sf(clean_dat, coords = c("lng", "lat"), crs = 4326, remove = FALSE)
leaflet(starbucks) %>%
addTiles() %>%
addMarkers(label = ~name) %>%
addProviderTiles("CartoDB") %>%
setView(lng = -46.65590, lat = -23.561197, zoom = 12)Vale notar que dados extraídos a partir de webscraping quase sempre apresentam algum ruído. Neste caso, os dados parecem relativamente limpos após um pouco de limpeza. Os endereços nem sempre são muito instrutivos, como no caso “Rodovia Hélio Smidt, S/N”, mas isto acontece porque muitas unidades estão dentro de hospitais, shoppings ou aeroportos.
Com estes dados já podemos fazer análises interessantes. Podemos descobrir, por exemplo, que há 5 unidades da Starbucks apenas na Avenida Paulista.
starbucks %>%
filter(str_detect(street, "Avenida Paulista"))Simple feature collection with 4 features and 5 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -46.65895 ymin: -23.56784 xmax: -46.64809 ymax: -23.55785
Geodetic CRS: WGS 84
# A tibble: 4 × 6
index name street lat lng
* <dbl> <chr> <chr> <dbl> <dbl>
1 0 Shopping Top Center Avenida Paulista, 854 -23.6 -46.7
2 1 Paulista 500 Avenida Paulista, 500 -23.6 -46.6
3 2 Shopping Cidade São Paulo Avenida Paulista, 1154 -23.6 -46.7
4 5 Shopping Center 3 Avenida Paulista, 2064 -23.6 -46.7
geometry
* <POINT [°]>
1 (-46.6508 -23.56581)
2 (-46.64809 -23.56784)
3 (-46.65438 -23.5631)
4 (-46.65895 -23.55785)Podemos também contar o número de unidades em cada um dos aeroportos. Aparentemente, há 8 unidades no aeroporto de Guarulhos, o que me parece um número muito alto.
starbucks %>%
st_drop_geometry() %>%
filter(str_detect(name, "Aeroporto")) %>%
mutate(
name_airport = str_remove(name, "de "),
name_airport = str_extract(name_airport, "(?<=Aeroporto )\\w+"),
name_airport = if_else(is.na(name_airport), "Confins", name_airport),
.before = "name"
) %>%
count(name_airport, sort = TRUE)# A tibble: 9 × 2
name_airport n
<chr> <int>
1 Brasília 3
2 GRU 3
3 Confins 2
4 Galeão 2
5 Viracopos 2
6 Congonhas 1
7 Curitiba 1
8 Florianópolis 1
9 Santos 1Por fim, podemos notar que muitas das unidades do Starbucks se localizam dentro de shoppings. Uma conta simples mostra que cerca de 75 unidades estão localizadas dentro de shoppings, perto de 50% das unidades2.
starbucks %>%
st_drop_geometry() %>%
filter(str_detect(name, "Shopping|shopping")) %>%
nrow()[1] 58Construindo
A partir destes dados podemos acrescentar mais informação. A partir do geobr podemos identificar em quais cidades as unidades se encontram.
dim_city = geobr::read_municipality(showProgress = FALSE)
dim_city = st_transform(dim_city, crs = 4326)
sf::sf_use_s2(FALSE)
starbucks = starbucks %>%
st_join(dim_city) %>%
relocate(c(name_muni, abbrev_state), .before = lat)Agora podemos ver quais cidades tem mais Starbucks.
starbucks %>%
st_drop_geometry() %>%
count(name_muni, abbrev_state, sort = TRUE) # A tibble: 38 × 3
name_muni abbrev_state n
<chr> <chr> <int>
1 São Paulo SP 34
2 Rio De Janeiro RJ 9
3 Curitiba PR 7
4 Brasília DF 6
5 Campinas SP 6
6 Guarulhos SP 4
7 Jundiaí SP 4
8 Porto Alegre RS 4
9 Ribeirão Preto SP 3
10 Confins MG 2
# ℹ 28 more rowsOu seja, há mais Starbucks somente na Paulista do que em quase todas as demais cidades do Brasil.
Conclusão
O web scraping é uma técnica de extração de dados bastante popular que nos permite rapidamente construiur bases de dados interessantes. Neste caso, o processo foi bastante simples, mas como comentei, ele pode ser muito complexo. Em posts futuros vou explorar mais esta base de dados e mostrar com juntar estas informações com dados do Google Maps.
Footnotes
https://starbucks.com.br/public/img/icons/starbucks-nav-logo.svg↩︎
Aqui, estamos assumindo que o a tag “name” sempre inclui a palavra shopping se a unidade estiver dentro de um shopping. Eventualmente, este número pode estar subestimado se houver unidades dentro de shoppings que não tem a palavra “shopping” no seu nome. A rigor, também não verificamos se, de fato, a tag shopping sempre está associada a um shopping em atividade.↩︎
{kind=link}