#> Os pacotes necessários para acompanhar este post
library(ggplot2)
library(scales)
library(dplyr)
library(forcats)
library(stringr)
library(readr)
#> Importa os dados limpos da Zona OD.
pod <- read_csv("https://github.com/viniciusoike/restateinsight/raw/main/posts/ggplot2-tutorial/table_pod.csv")
#> Seleciona apenas zonas de São Paulo com população acima de zero
pod <- filter(pod, code_muni == 36, pop > 0)Escalas e Cores
Este post é o primeiro da série de tutoriais que não vai tratar de um tipo de gráfico ou, mais especificamente, de um tipo de geom. Escalas, no contexto do ggplot2 são tanto os eixos do gráfico como as suas cores, quando usa-se a função aes para mapear alguma variável em cores. As funções scale_* controlam todos os aspectos das escalas, incluindo as cores e as suas respectivas legendas.
Alguns aspectos mais detalhados das escalas, como a fonte do texto, o tamanho, etc. são controlados por uma função mais específica theme. Em alguns exemplos deste post eu apresento como utilizar esta função, mas uma apresentação mais formal fica postergada para outro momento. A função theme é talvez a mais burocrática e complexa do pacote ggplot2.
O código abaixo lista os pacotes necessários para acompanhar este post.
Para este post, além das bases de dados que já acompanham o pacote ggplot2 também uso a base da Pesquisa Origem e Destino (POD) de São Paulo, de 2018. A POD é uma pesquisa feita pela companhia Metrô de São Paulo que compila informações sobre os deslocamentos diários da população da Região Metropolitana de São Paulo. Além de dados sobre mobilidade, a POD também reúne uma série de informações socioeconômicas. Os dados são agregados a nível de Zona Origem e Destino ou Zona OD; as zonas OD são subconjuntos de distritos de São Paulo e das demais cidades da Região Metropolitana e, na prática, são como bairros de cada cidade1.
Eu mesmo tratei a base e as funções utilizadas para montar esta tabela estão disponíveis no repositório {tidypod} do meu GitHub.
Neste post vou explorar apenas as zonas OD da cidade de São Paulo, excluindo as zonas “não-residenciais”, como a Cidade Universitária (campus da USP).
Escalas
Escalas, no contexto do ggplot, significam tanto a manipulação dos eixos do gráfico como das cores dos elementos. Há uma infinidade de funções scale_* e não vale a pena entrar nos detalhes de cada uma delas. Neste post vou discutir a lógica geral destas funções e apresentar aquelas que acredito que possam ser as mais úteis.
O uso de escalas de cores e legendas está intimamente ligado ao tipo de variável que se está visualizando. Para entender melhor o funcionamento das escalas é preciso compreender o tipo de variável que se vai plotar e como o R interpreta esta variável. A próxima seção vai revisar a distinção entre variáveis contínuas e variáveis discretas e como estes dados são processados e armazenados no R.
Tipos de variáveis
O ggplot, grosso modo, divide as variáveis em contínuas e discretas. As variáveis contínuas, em geral, são numéricas e podem assumir qualquer valor; já as variáveis discretas costumam ser “categóricas” e são “contáveis”. O preço de um imóvel, por exemplo, é uma variável contínua. Já uma variável que categoriza um imóvel entre “casa” e “apartamento” é uma variável discreta.
Esta lógica é aplicada nas funções que controlam os eixos x e y de um gráfico.
scale_y_continuous()scale_y_discrete()scale_x_continuous()scale_x_discrete()
Uma lógica muito similar se aplicas às principais funções que controlam as cores e a legenda de cores de um gráfico:
scale_color_continuous()scale_color_discrete()scale_fill_continuous()scale_fill_discrete()
Mesmo quando modificamos outros aspectos estéticos do gráfico como size e alpha temos:
scale_alpha_continuous()scale_alpha_discrete()scale_size_continuous()scale_size_discrete()
Variáveis contínuas
Uma variável contínua costuma representar algum número. No R há várias formas de armazenar números, mas isto não costuma ser muito relevante para a tarefa de visualização dos dados. Na maior parte dos casos, basta garantir que a coluna numérica em questão seja um número usando is.numeric() ou as.numeric().
Como mencionado acima, exemplos comuns de variáveis contínuas são: preço de um imóvel, salário de um indivíduo, a taxa de inflação num mês, etc.
Variáveis discretas
Uma variável discreta costuma representar uma categoria. No R existe uma classe especial de variável para armazenar este tipo de dado chamada factor. Um factor é um vetor de texto ou de números que segue uma ordem. Além de ter uma ordem, cada elemento pode ter um label.
factor(x = c(...), levels = c(...), labels = c(...))Para se definir um factor basta usar a função homônima. Note que na ausência de uma ordem explicitamente definida, o R organiza o vetor em ordem alfabética. Se, ao invés de um vetor de texto tivéssemos usado um vetor de números, eles teriam sido ordenados no sentido ascedente (do menor para o maior).
Para acessar a ordem do factor pode-se usar a função order() ou, mais especificamente, a função levels().
#> Criando um factor
medalhas <- factor(c("ouro", "prata", "bronze"))
#> [1] ouro prata bronze
#> Levels: bronze ouro prata
#> Conferindo a ordem dos elementos
order(medalhas)
#> [1] 3 1 2
levels(medalhas)
#> [1] "bronze" "ouro" "prata" O código abaixo recria o factor, deixando mais explícito a estrutura deste tipo de objeto. Note que o argumento levels e labels não precisam ser repetidos.
#> Criando um factor
medalhas <- factor(
c("ouro", "prata", "bronze", "bronze", "ouro", "bronze"),
levels = c("bronze", "prata", "ouro"),
labels = c("Bronze", "Prata", "Ouro")
)
medalhas
#> [1] Ouro Prata Bronze Bronze Ouro Bronze
#> Levels: Bronze Prata OuroTrabalhar com factors pode ser uma tarefa bastante frustrante. Neste sentido, recomendo muito o uso do pacote forcats, que provê uma série de funções fct_* que facilitam muito a manipulação deste tipo de objeto. Os exemplos abaixo mostram algumas das funções mais úteis deste pacote.
df <- data.frame(
x = c(5, 2, 3),
y = factor(c("bronze", "prata", "ouro"))
)
#> Troca a ordem do factor segundo algum outro vetor
fct_reorder(df$y, df$x)
#> [1] bronze prata ouro
#> Levels: prata ouro bronze
#> Troca os labels do factor usando uma função
fct_relabel(df$y, toupper)
#> [1] BRONZE PRATA OURO
#> Levels: BRONZE OURO PRATA
#> Troca os labels do factor manualmente
fct_recode(df$y, "Bronze" = "bronze")
#> [1] Bronze prata ouro
#> Levels: Bronze ouro prata
#> Conta a ocorrência de cada factor
fct_count(df$y)
#> A tibble: 3 × 2
#> f n
#> <fct> <int>
#> 1 bronze 1
#> 2 ouro 1
#> 3 prata 1Por fim, vale comentar brevemente sobre uma particularidade de um factor criado a partir de uma variável numérica. Para converter um factor de texto em character basta usar as.character(x). Para converter de volta um factor de números é preciso usar as.numeric(as.character(x)).
x <- c(1, 10, 2, 5, 1)
y <- as.factor(x)
#> Por padrão, as.numeric retorna a ordem do factor. Equivalente a order()
as.numeric(y)
#> [1] 1 4 2 3 1
#> Para converter de volta no número original
as.numeric(as.character(y))
#> [1] 1 10 2 5 1Escalas: o básico
Escalas Contínuas
Vamos começar com um gráfico simples que mostra a renda domiciliar média da Zona OD no eixo-x e o número médio de carros por domicílio no eixo-y.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point()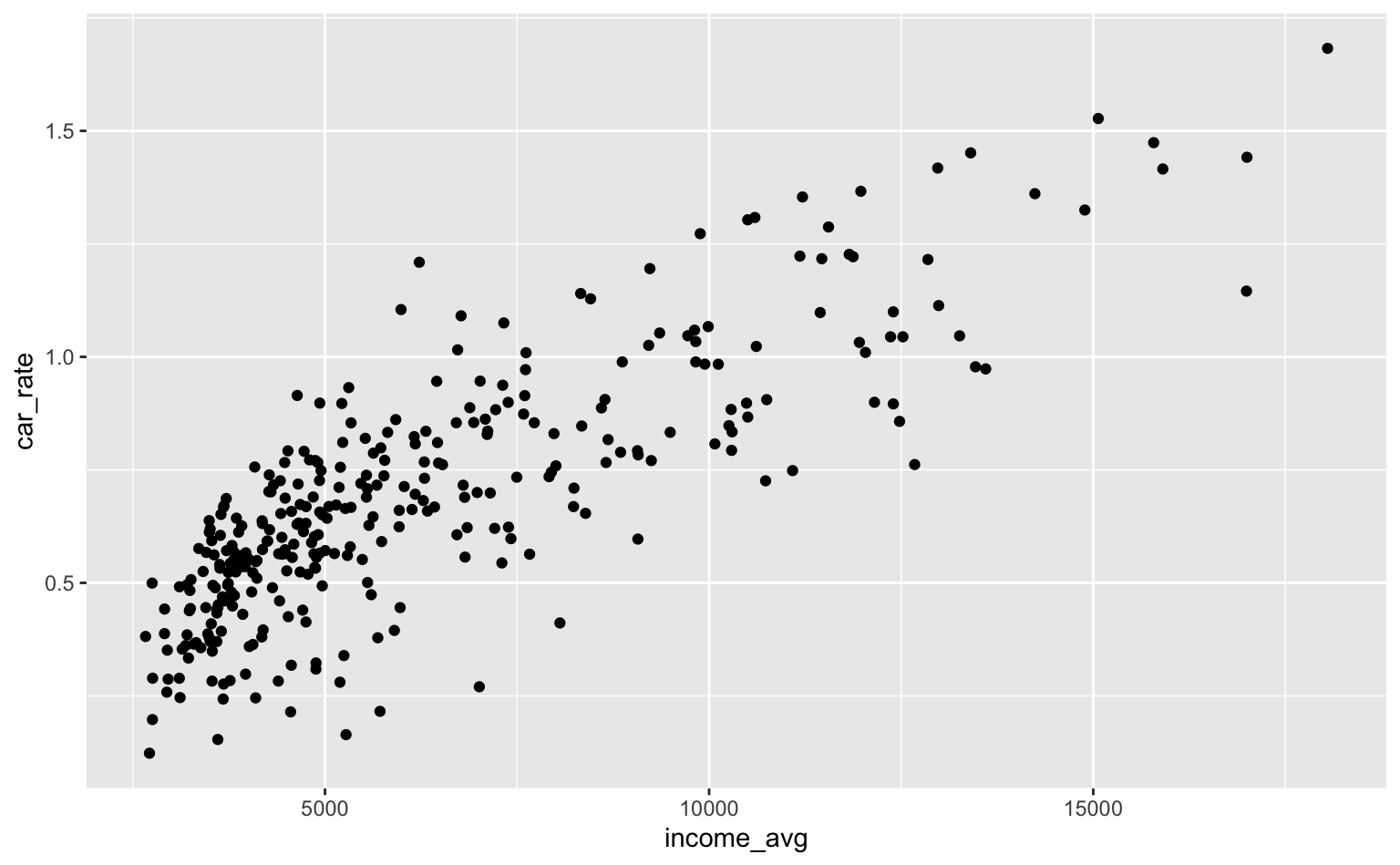
No caso do gráfico acima, ambas as variáveis são contínuas, portanto, para alterar algum dos eixos usa-se as funções scale_x_continuous() e scale_y_continuous(). Estas funções tem 5 argumentos principais: name, breaks, labels, limits e expand.
O argumento name define o título do eixo. Alternativamente, pode-se usar a função labs, como fizemos em posts anteriores.
#> Define o título de cada eixo usando as funções scale
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(name = "Renda Domiciliar Média (R$)") +
scale_y_continuous(name = "Automóveis por domicílio")
#> Define o título de cada eixo usando a função labs
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
labs(x = "Renda Domiciliar Média (R$)", y = "Automóveis por domicílio")
Para controlar as ‘quebras’ do eixo-x (os pontos onde aparece cada número) usa-se o argumento breaks.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(breaks = seq(0, 20000, 2500))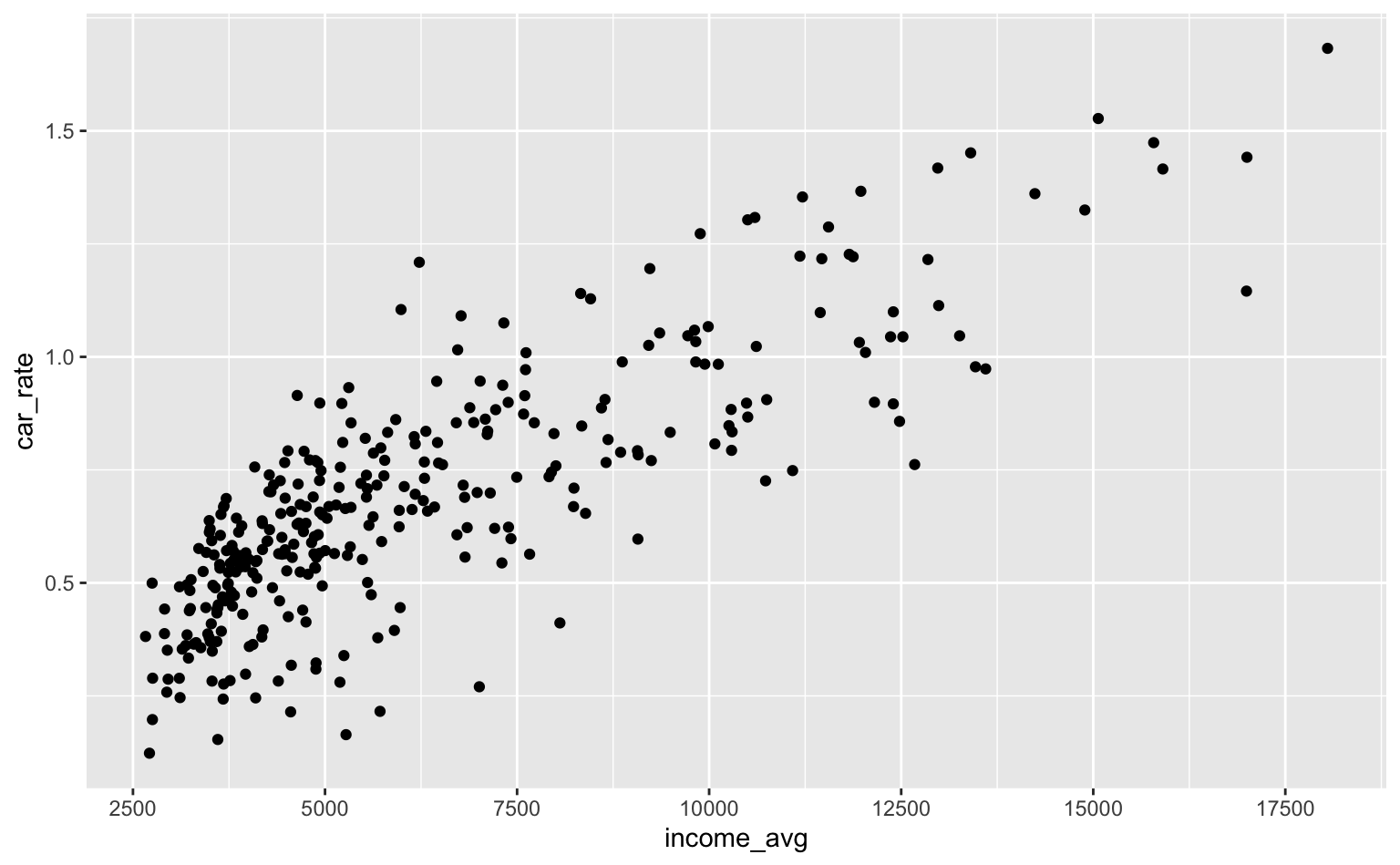
Por padrão, o número exibido no gráfico é igual ao argumento fornecido em breaks, mas pode-se alterar isto usando labels. Para ser mais preciso: breaks define a posição onde o labels vai ser exibido.
No exemplo abaixo uso o fato do salário mínimo, à época da pesquisa, ser de R$954.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(
breaks = 954 * c(2, 4, 6, 10, 15),
labels = stringr::str_glue("{c(2, 4, 6, 10, 15)} S.M.")
)
O argumento labels pode ser qualquer texto, desde que ele tenha o mesmo número de elementos que o argumento breaks. O pacote scales oferece algumas funções label_* pré-definidas que auxiliam a formatar as escalas. O exemplo abaixo mostra como usar a função label_dollar para formatar o eixo-x.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(
breaks = seq(0, 20000, 2500),
labels = label_dollar(big.mark = ".")
)
Na minha experiência, as funções mais úteis do pacote são:
label_number(): usado para formar números de maneira gerallabel_percent(): usado para formatar números expressados percentualmentelabel_dollar(): usado para formatar números que representam dinheiro
Para seguir o padrão brasileiro, utiliza-se big.mark = "." e decimal.mark = ",".
Para dar um “zoom-in” no gráfico pode-se alterar o argumento limits. Este argumento recebe um par de números para definir o número máximo e mínimo que deve ser plotado. Para deixar o eixo “livre” basta definir o valor como NA.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(limits = c(3000, 5000)) +
scale_y_continuous(limits = c(NA, 1))
Por fim, o argumento expand diminui ou aumenta a distância entre o gráfico e o limite dos eixos. A aplicação mais comum disso é para reduzir o espaço em branco que “sobra” em alguns gráficos.
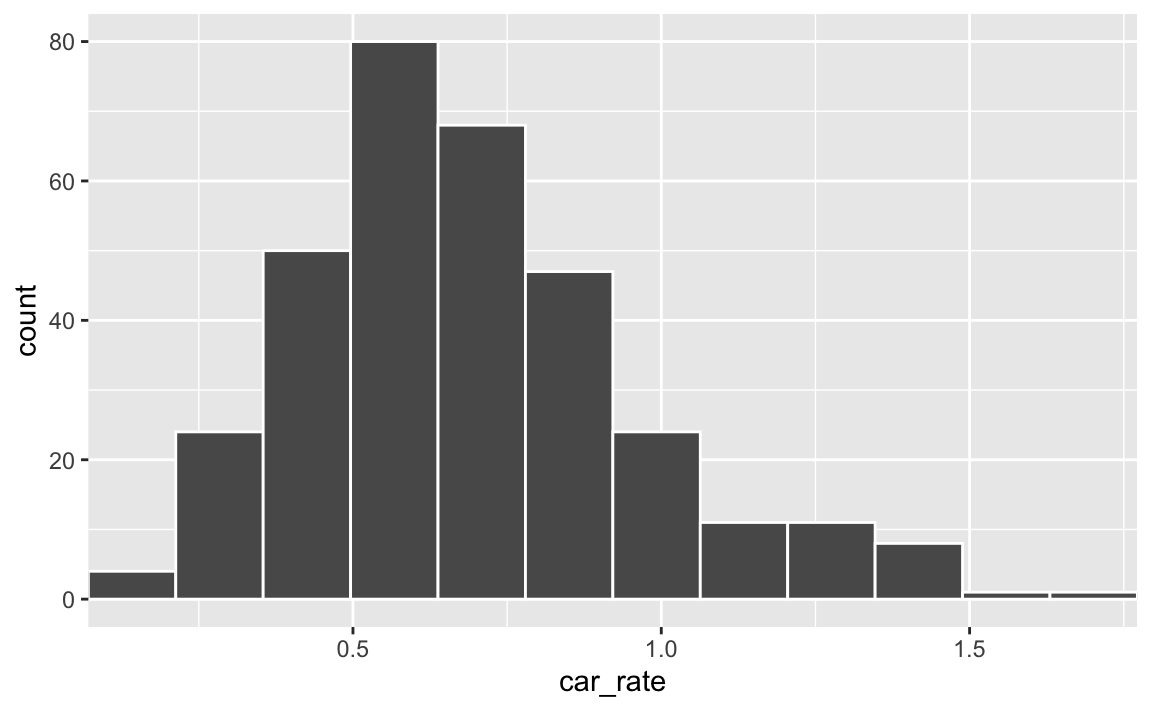
O par de histogramas abaixo mostra a distribuição do número médio de automóveis por domicílio entre as zonas OD.
ggplot(pod, aes(x = car_rate)) +
geom_histogram(bins = 12, color = "white")
ggplot(pod, aes(x = car_rate)) +
geom_histogram(bins = 12, color = "white") +
scale_x_continuous(expand = c(0, 0))
Escalas discretas
Escalas discretas funcionam praticamente da mesma forma. Uma distinção importante é que, no caso de uma variável discreta ou categórica, o eixo - por padrão - vai plotar o label da variável.
O código abaixo encontra os 5 distritos mais populosos de São Paulo.
#> Seleciona os cinco distritos mais populosos
dstr_pop <- pod |>
#> Soma a variável pop em cada distrito
summarise(total_pop = sum(pop), .by = "name_district") |>
#> Encontra os cinco valores mais elevados
slice_max(total_pop, n = 5) |>
#> Converte a variável `name_district` para factor
mutate(name_district = factor(name_district))
ggplot(dstr_pop, aes(x = name_district, y = total_pop)) +
geom_col()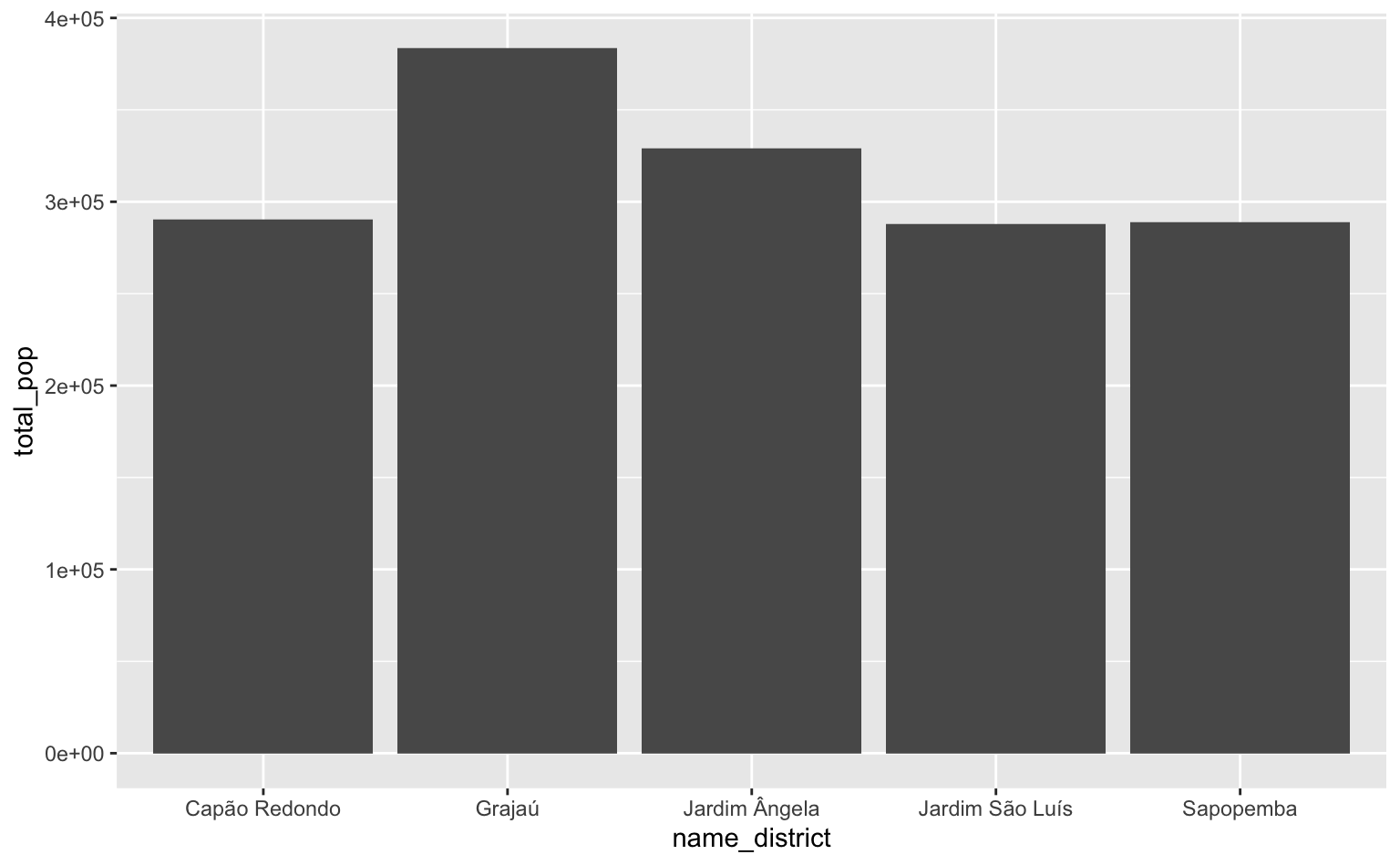
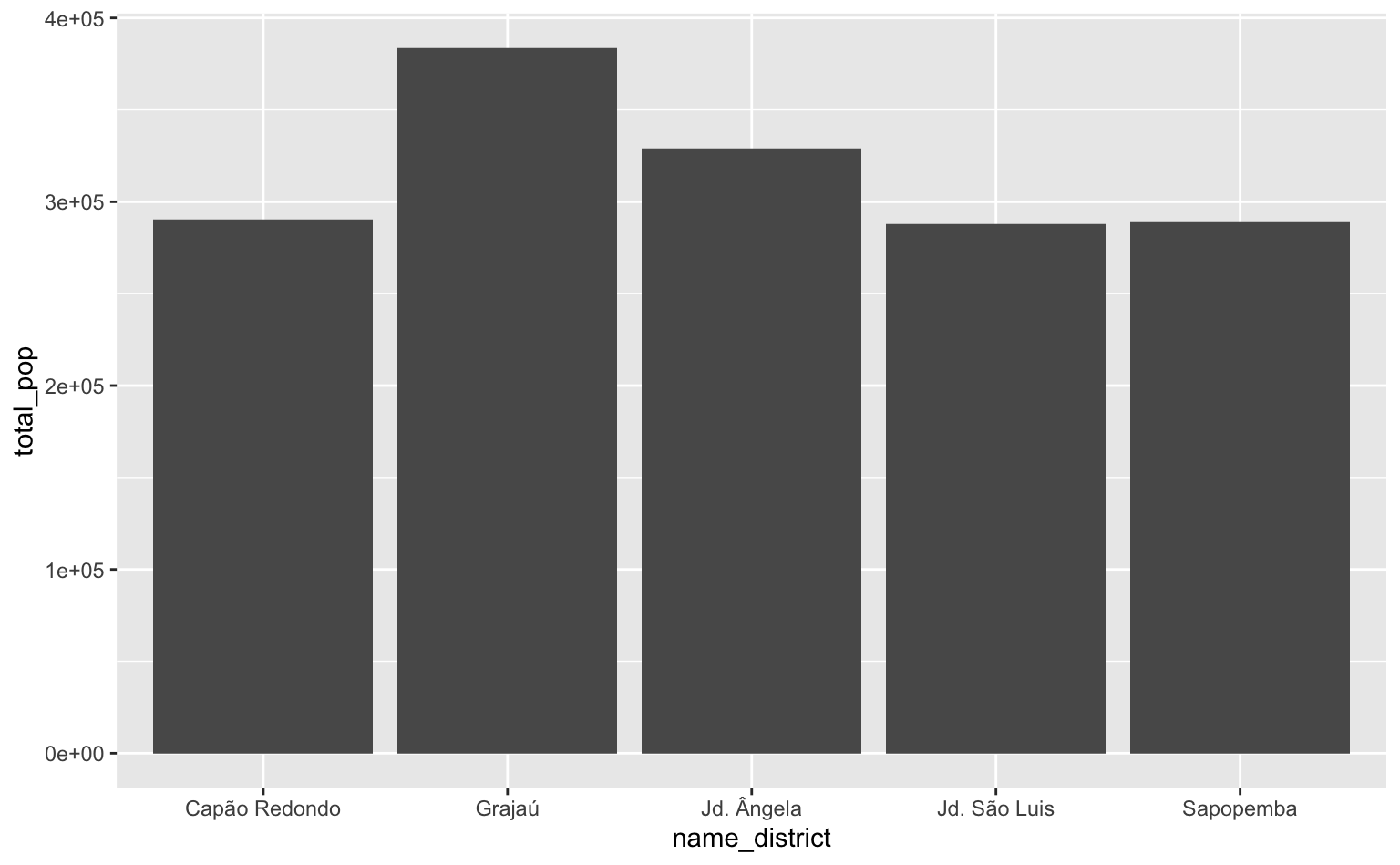
Caso não se queira alterar o tipo da variável é possível definir os labels diretamente na função scale_x_discrete().
ggplot(dstr_pop, aes(x = name_district, y = total_pop)) +
geom_col() +
scale_x_discrete(
labels = c("Capão Redondo", "Grajaú", "Jd. Ângela", "Jd. São Luis",
"Sapopemba")
)
Por fim, vale notar que o argumento labels aceita uma função. Neste caso, fornece-se apenas o nome da função, sem argumentos explícitos. O gráfico abaixo mostra quatro exemplos.
base_plot <- ggplot(dstr_pop, aes(x = name_district, y = total_pop)) +
geom_col() +
coord_flip() +
labs(x = NULL, y = NULL)
#> Texto maísculo
base_plot + scale_x_discrete(labels = stringr::str_to_upper)
#> Texto minúsculo
base_plot + scale_x_discrete(labels = stringr::str_to_lower)
#> Texto em formato de 'título'
base_plot + scale_x_discrete(labels = stringr::str_to_title)
#> Quebras de linha automáticas no texto
base_plot + scale_x_discrete(labels = \(x) stringr::str_wrap(x, width = 8))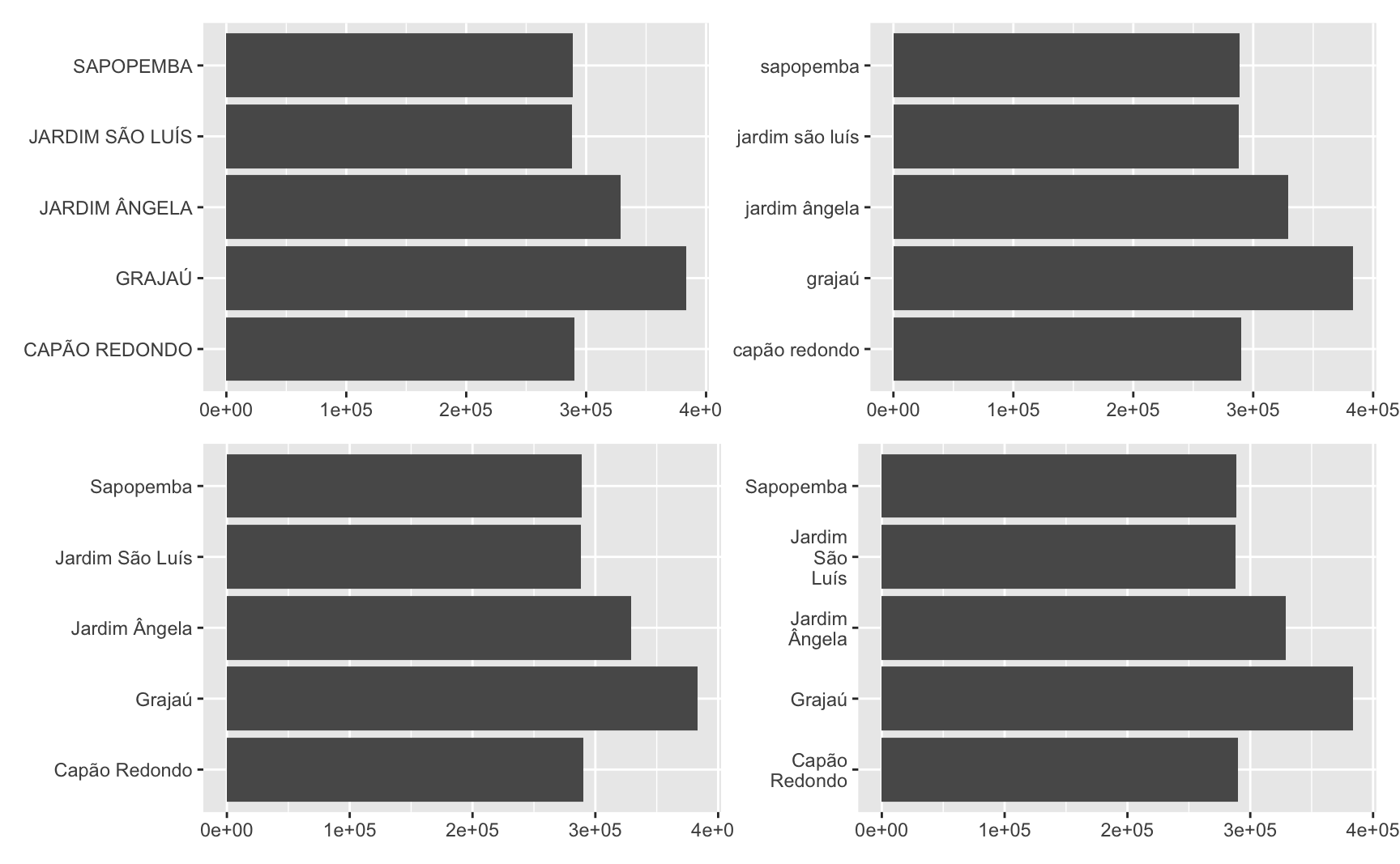
No exemplo acima, utiliza-se a função stringr::str_to_upper para converter o texto do eixo x para maiúsculo.
No caso de uma função que precisa de um argumento adicional, como é o caso da função stringr::str_wrap é preciso criar uma ‘função anônima’. Uma função anônima funciona exatamente como uma função convencional e permite que um argumento adicional seja inserido.
A sintaxe para definir uma função anônima é simplesmente function(x) g(x, ...) onde g(x) é alguma função qualquer. Por exemplo. function(x) mean(x, na.rm = TRUE). Alternativamente, é possível definir uma função anônima simplesmente com \(x).
Um pouco mais de escalas
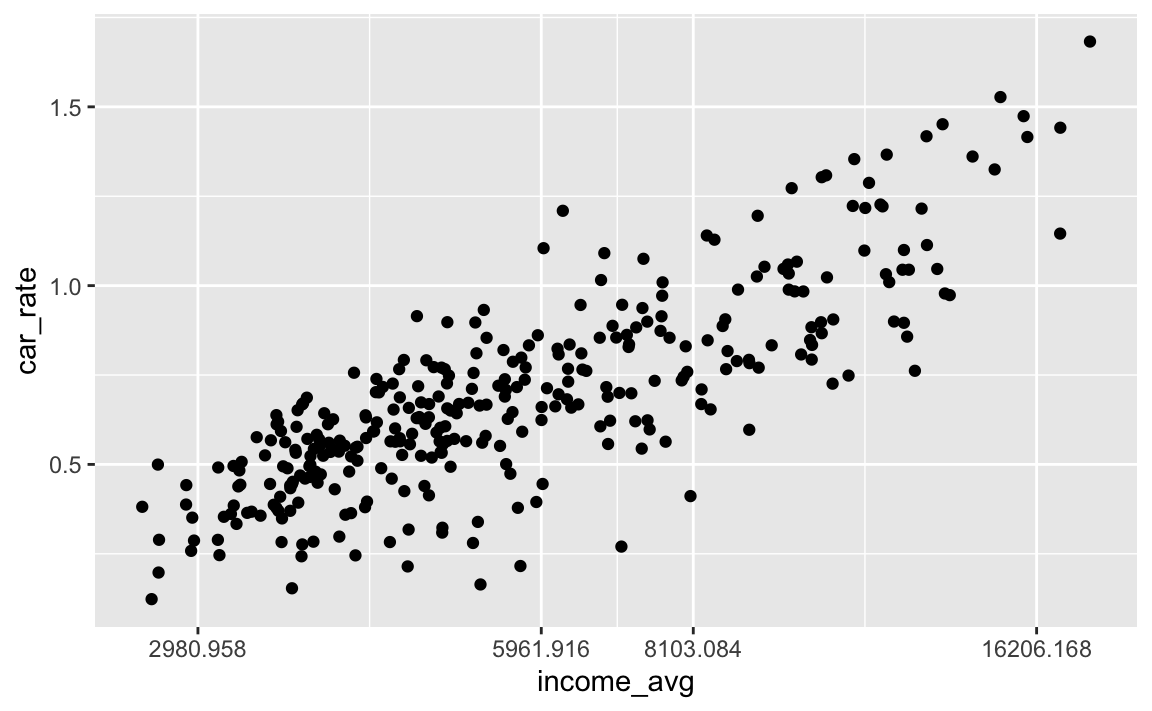
Além das funções scale_* há também algumas mais específicas. O código abaixo apresenta a função scale_x_log10() que, como o nome sugere, aplica uma transformação log na variável x.
Uma das vantagens de usar esta função, ao invés de transformar os dados usando a função log(), ou mesmo de usar trans = 'log' dentro de scale_x_continuous(), é que as quebras do eixo-x fiquem num formato num formato mais bonito como se vê abaixo.
De maneira geral, a função scale_x_log10() é útil quando há variância crescente nos dados ou a variável segue algum tipo de crescimento exponencial.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_log10()
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point() +
scale_x_continuous(trans = "log")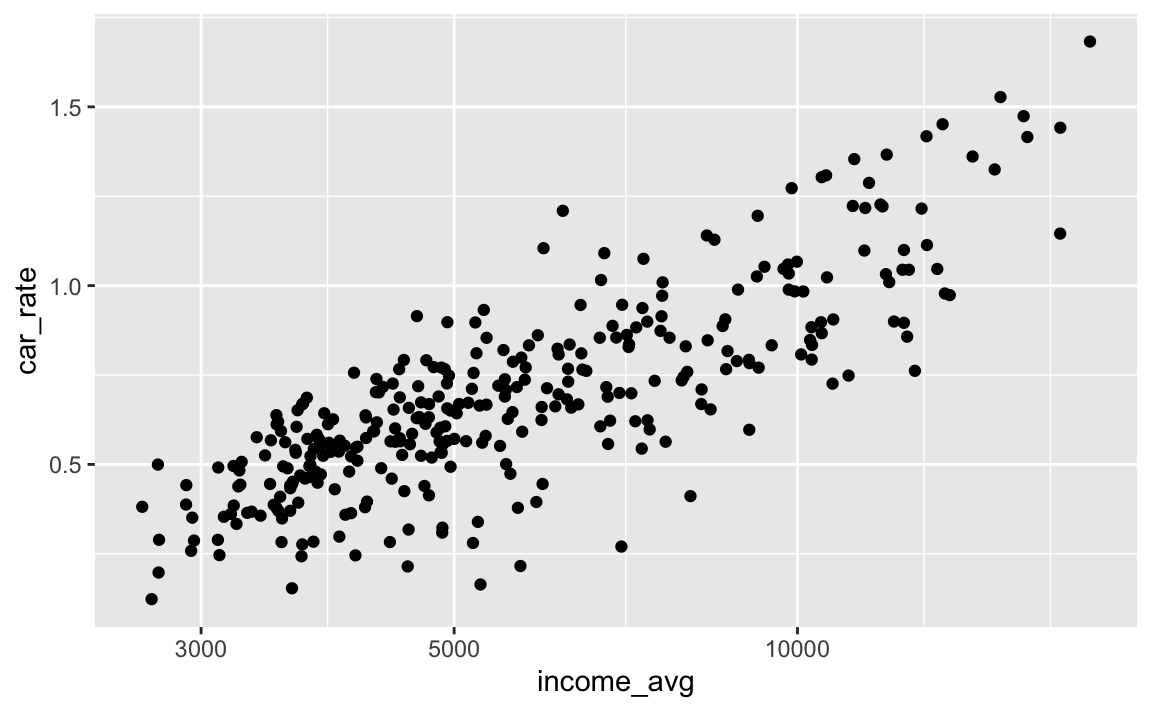
Outra função interessante que eventualmente pode ser útil é a scale_*_reverse() que inverte a direção dos dados. Esta função é muito mais prática do que, por exemplo, trocar o sinal do dado original e aí utilizar o argumento labels para ajustar os números.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_count() +
scale_y_reverse()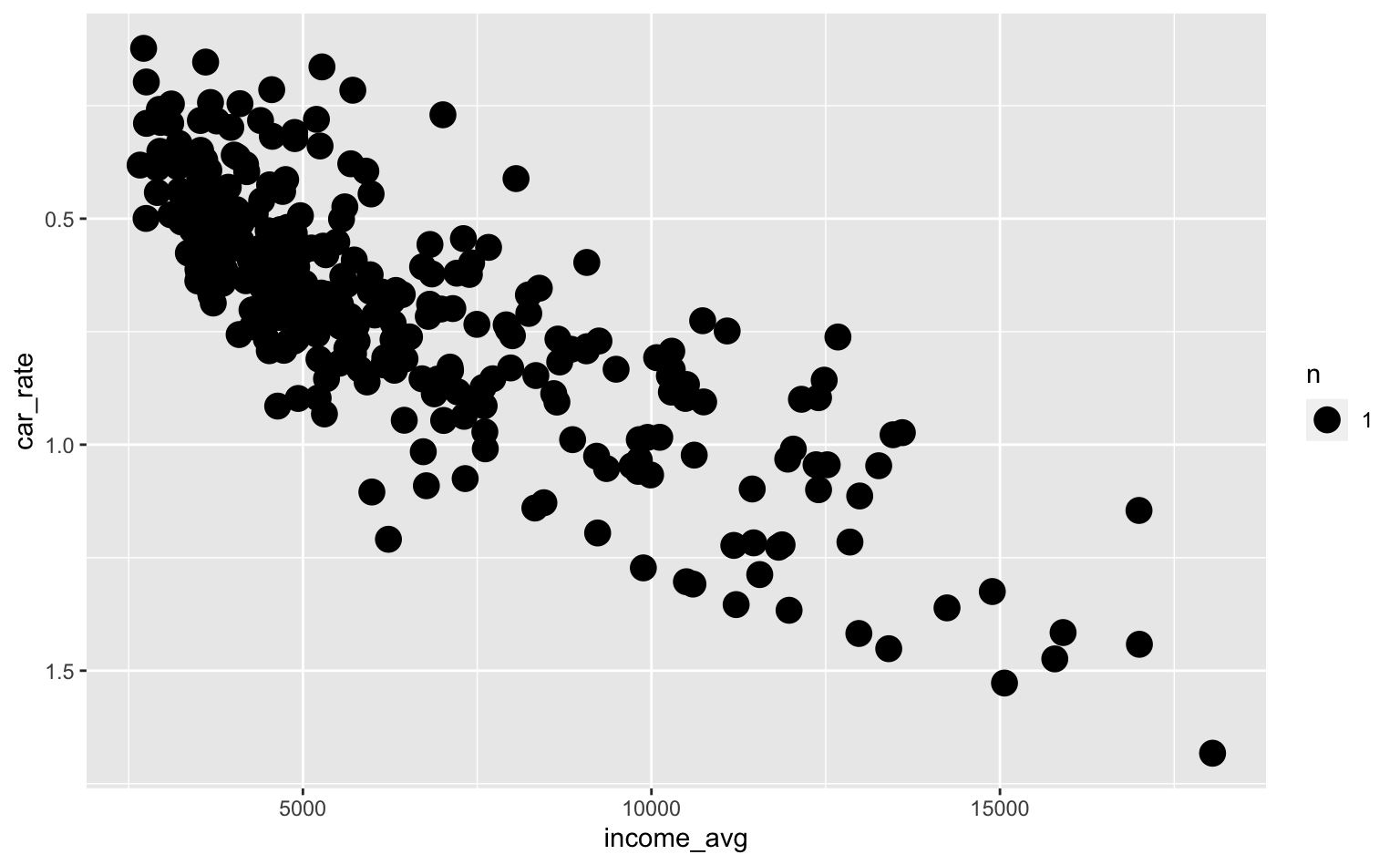
Por fim, outra função interessante é a scale_*_binned(), que ajuda a discretizar uma varíalvel contínua. Ela funciona de maneira similar a um historgrama, argupando uma variável contínua em grupos: isto facilita a observação de padrões nos dados. No caso do gráfico abaixo, vê-se que o grupo mais comum é de zonas com renda entre R\$4000 e R\$6000 com número médio de automóveis por domicílios entre 0,6 e 0,8.
ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_count() +
scale_x_binned() +
scale_y_binned()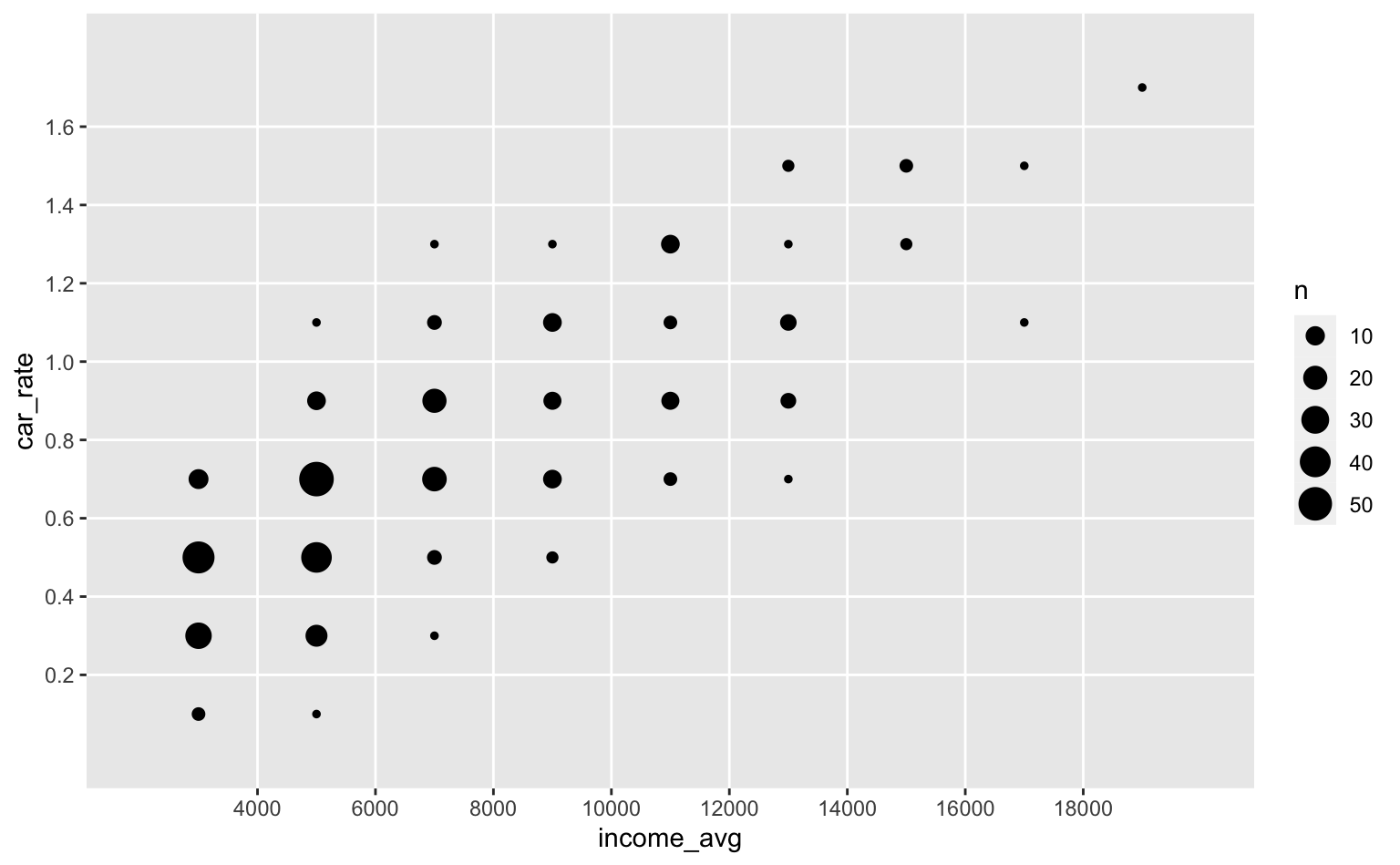
Datas
Um dado em formato de data é significativamente mais complicado do que as variáveis contínuas e discretas que vimos acima. Existem inúmeros formatos distintos para se apresentar datas que variam de local para local; além disso, pode ser necessário lidar com fusos horários, feriados, anos bissextos, etc.
Idealmente, toda coluna com datas deve sempre estar no formato YYYY-MM-DD, isto é, 2014-01-15 (15 de janeiro de 2014). Para converter um character em Date basta usar a função as.Date. Se a data não estiver no formato YYYY-MM-DD será necessário especificar o formato usando o argumento format. Para casos mais complexos recomendo o uso do pacote {lubridate}.
x <- c("2014-01-01", "2014-02-01")
y <- c("01/01/2014", "01/02/2014")
as.Date(x)
#> [1] "2014-01-01" "2014-02-01"
as.Date(y, format = "%d/%m/%Y")
#> [1] "2014-01-01" "2014-02-01"Como datas têm uma classe especial elas, por conseguinte, têm também algumas funções dedicadas. A função scale_x_date tem dois argumentos principais2:
date_breaks: que aceita valores como “1 year”, “3 months”, etc.date_labels: que aceita valores como “%Y%m%d”, “%Y%b”, etc.
Vou apresentar esta função de maneira breve, diretamente atráveis de exemplos. O exemplo abaixo mostra o funcionamento geral desta função.
ggplot(economics, aes(x = date, y = psavert)) +
geom_line() +
scale_x_date(date_breaks = "5 year", date_labels = "%Y")
O próximo exemplo mostra como exibir o número do ano junto com a nome abreviado do mês. Note como o uso de \n quebra a linha no eixo-x.
prices_austin <- txhousing %>%
filter(city == "Austin", year %in% 2007:2011) %>%
mutate(date = lubridate::make_date(year, month))
ggplot(prices_austin, aes(x = date, y = sales)) +
geom_line() +
scale_x_date(date_breaks = "3 month", date_labels = "%Y\n%b")
Para escolher datas específicas, usa-se o argumento convencional breaks.
datas <- c(as.Date("2007-01-01"), as.Date("2008-07-30"), as.Date("2010-03-01"))
ggplot(prices_austin, aes(x = date, y = sales)) +
geom_line() +
scale_x_date(breaks = datas, date_labels = "%Y\n%b")
O exemplo abaixo pula alguns passos, já que ainda não se apresentou formalmente a função theme. Essencialmente, a função theme diminui o número de linhas verticais no fundo do gráfico e gira o texto do eixo-x em 90 graus.
prices_austin10 <- txhousing %>%
filter(city == "Austin", year %in% 2010:2011) %>%
mutate(date = lubridate::make_date(year, month))
ggplot(prices_austin10, aes(x = date, y = sales)) +
geom_line() +
scale_x_date(
breaks = seq(as.Date("2010-01-01"), as.Date("2011-12-01"), by = "month"),
date_labels = "%Y-%m"
) +
theme(
panel.grid.minor = element_blank(),
axis.text.x = element_text(angle = 90)
)
A tabela abaixo resume como funciona a codificação dos padrões de datas. Vale notar que os inputs %b e %B usam o nome dos meses definidos ou pelo sistema operacional ou pelo padrão de locale do R. O mesmo vale para %A e outras que imprimem algum texto.
Para consultar o padrão do seu computador veja Sys.getlocale(). Para trocar o padrão usa-se Sys.setlocale(), mas recomendo evitar este tipo de comando a não ser que você saiba o que está fazendo. É importante reforçar que não basta somente definir um date_labels apropriado, é preciso também que o dado esteja no formato correto.
| Input | Label |
|---|---|
| %Y | Ano completo (e.g. 2010) (0000-9999) |
| %y | Ano abreviação (e.g. 10) (00-99) |
| %m | Mês em número (e.g. 11) (01-12) |
| %b | Mês abreviação (e.g. Jan) (Jan-Dec) |
| %B | Mês completo (e.g. January) (January-December) |
| %d | Dia do mês (e.g. 02) (01-31) |
| %a | Dia da semana, abreviação (Mon-Sun) |
| %A | Dia da semana, completo (Monday-Sunday) |
| %I | Hora, no padrão 12 horas (01-12) |
| %H | Hora, no padrão 24 horas (00-23) |
Cores
Em posts anteriores, vimos que o ggplot mapeia elementos estéticos em elementos visuais no gráfico. Neste sentido, pode-se fazer com que as cores do gráfico representem alguma variável dos dados. Há dois tipos de “cores”: color e fill. Grosso modo, color é utilizado para desenhar o contorno de objetos ou alguns objetos pequenos, enquanto fill é utilizado para preencher objetos.
No histograma abaixo isto fica evidente: a cor fornecida para o argumento color é mapeada no contorno da barra, enquanto a cor fornecida para fill preenche a barra.
ggplot(pod, aes(x = car_rate)) +
geom_histogram(bins = 12, color = "white", fill = "dodgerblue4")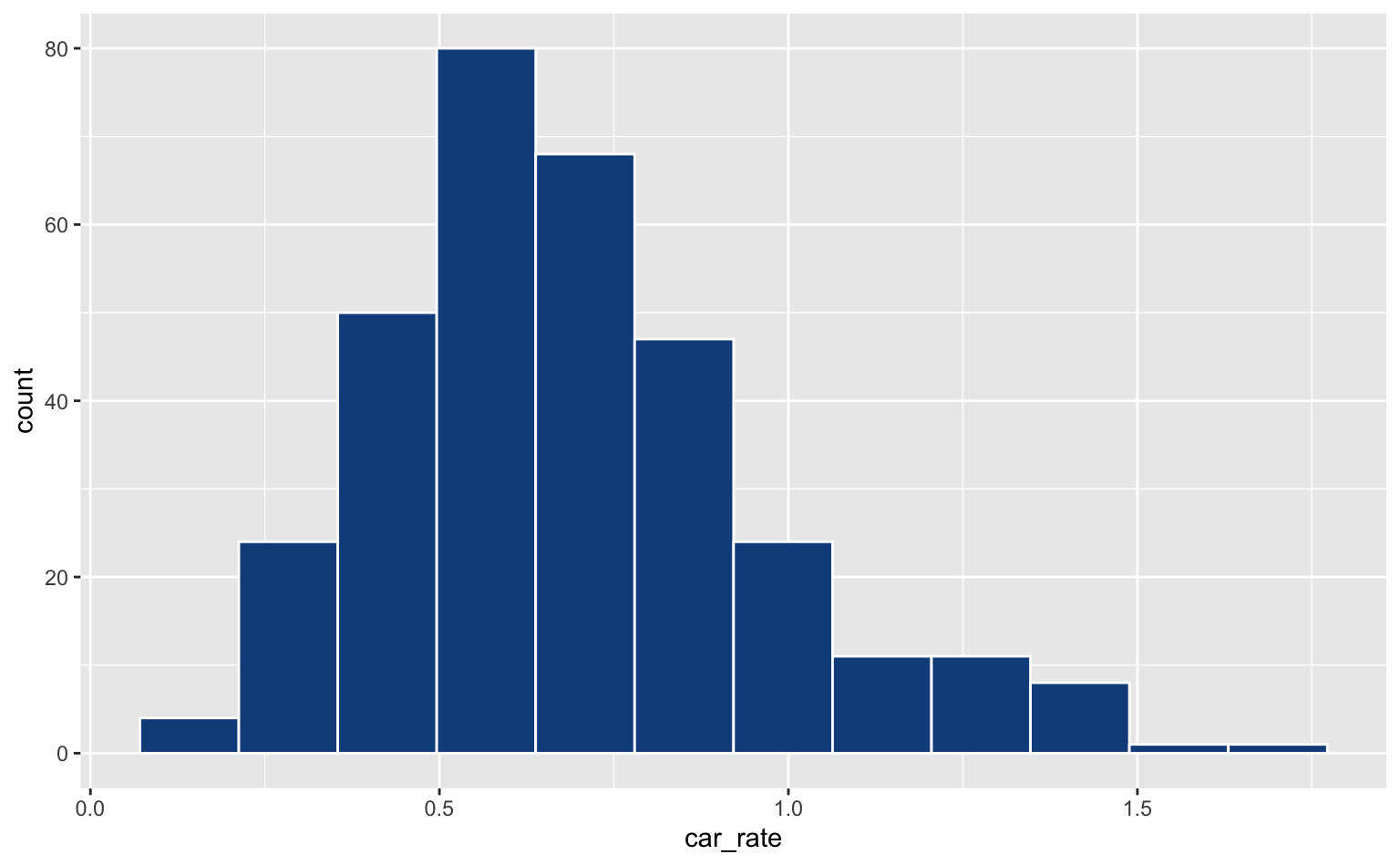
Há dois casos gerais para se pensar o uso de cores no ggplot. Caso você já tenha uma pré-seleção de cores, basta usar scale_color_manual() ou scale_fill_manual(). Caso você não tenha uma paleta de cores pré-definida será necessário depender de alguma das várias funções do ggplot como:
scale_color_brewer()scale_color_distiller()scale_color_grey()scale_color_viridis_*()
Além das funções do pacote ggplot2 há diversos pacotes que oferecem paletas de cores adicionais como:
No restante deste post vou mostrar como alterar as cores de um gráfico, mas não vou discutir aspectos técnicos sobre a escolha de cores3.
Cores: o básico
Variáveis discretas
Novamente, vamos começar com um exemplo simples. O código abaixo seleciona algumas Zonas OD e ranqueia elas segundo a variável prop_educ_superior que é o percentual de indivíduos (naquela Zona) com ensino superior.
zonas <- c("Vila Mariana", "Paraíso", "Saúde", "Jabaquara", "Grajaú")
subpod <- pod %>%
filter(name_zone %in% zonas) %>%
mutate(
name_zone = factor(name_zone),
name_zone = fct_reorder(name_zone, prop_educ_superior)
)Usando o argumento aes sabemos que é possível mapear uma cor diferente para cada uma das regiões como no gráfico abaixo.
ggplot(subpod, aes(x = name_zone, y = prop_educ_superior)) +
geom_col(aes(fill = name_zone))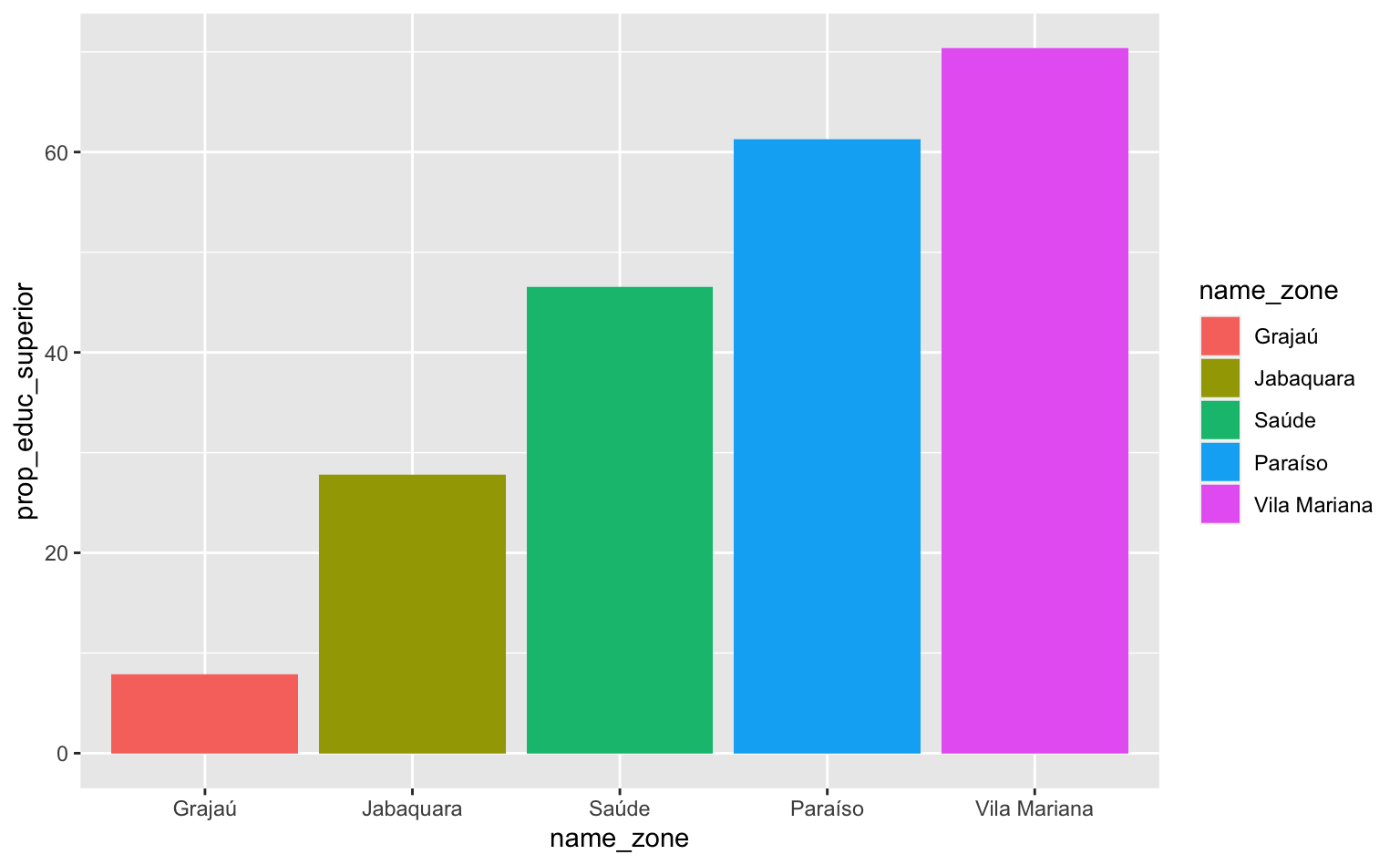
Para trocar as cores usamos a função scale_fill_manual. Note que uso a função scale_fill_* pois quero trocar as cores do fill. Vale notar que, neste caso, a função scale_fill_discrete atingiria o mesmo resultado.
cores <- c("#C0D1B6", "#A3C9A8", "#84B59F", "#69A297", "#50808E")
ggplot(subpod, aes(x = name_zone, y = prop_educ_superior)) +
geom_col(aes(fill = name_zone)) +
scale_fill_manual(values = cores)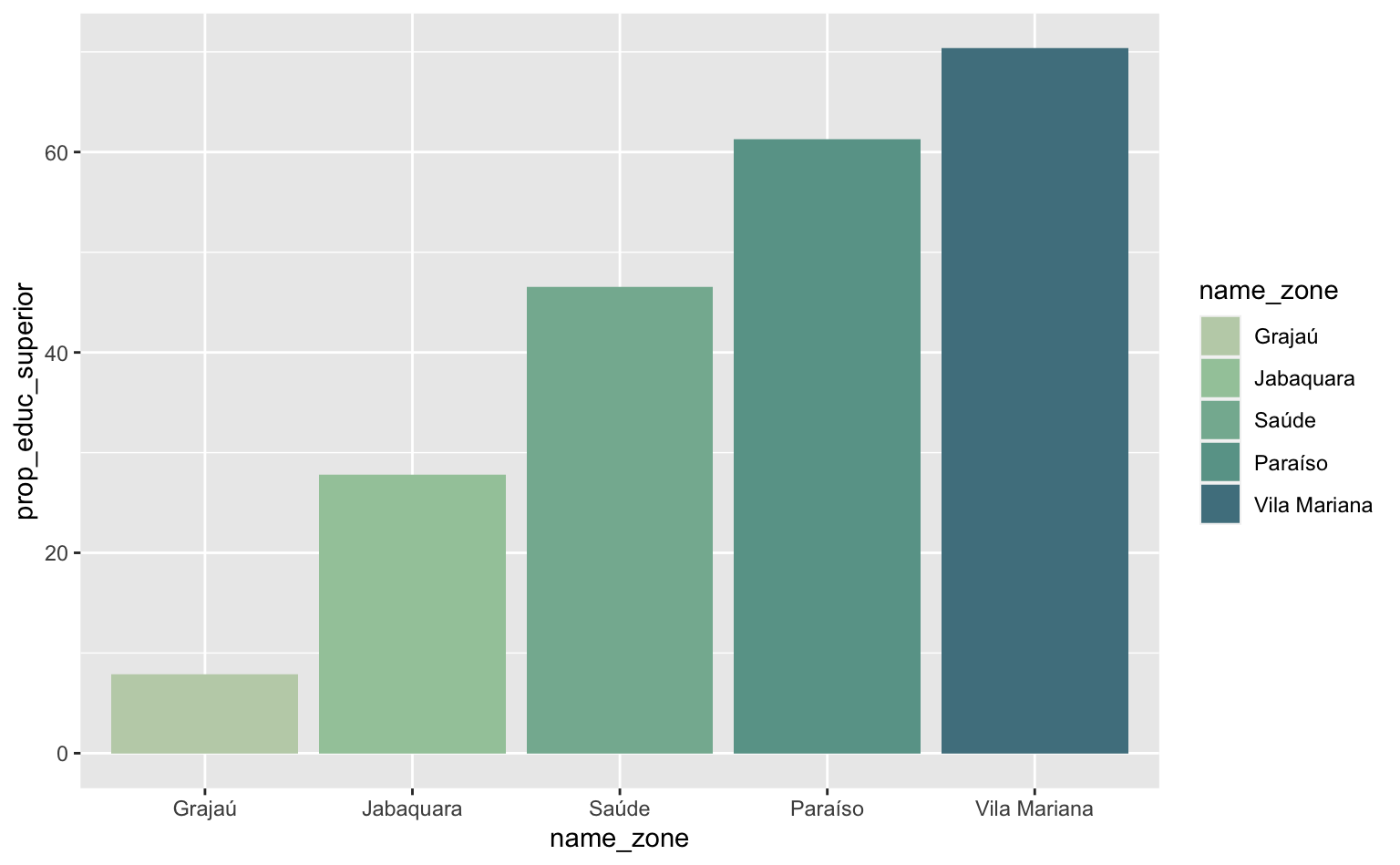
Note que os mesmos argumentos name, labels, etc. continuam valendo.
ggplot(subpod, aes(x = name_zone, y = prop_educ_superior)) +
geom_col(aes(fill = name_zone)) +
scale_fill_manual(
name = "ZONAS",
values = cores,
labels = toupper
)
Para controlar os detalhes da legenda de cores usa-se a função guide em conjunto com a função guide_legend. Os exemplos abaixo mostram algumas das customizações possíveis. Para mais detalhes vale conferir a página de ajuda da função guide_legend.
base_plot <- ggplot(subpod, aes(x = name_zone, y = prop_educ_superior)) +
geom_col(aes(fill = name_zone)) +
scale_fill_manual(name = "Zona", values = cores) +
labs(x = NULL, y = NULL) +
scale_x_discrete(labels = c("GRA", "JAB", "SAU", "PAR", "VMR"))
#> Remove a legenda
base_plot + guides(fill = "none")
#> Posiciona o título da legenda em baixo
base_plot + guides(fill = guide_legend(title.position = "bottom"))
#> Centraliza o texto da legenda
base_plot + guides(fill = guide_legend(
label.position = "left", label.hjust = 0.5, title.hjust = 0.5
))
#> Inverte a disposição da legenda
base_plot + guides(fill = guide_legend(reverse = TRUE))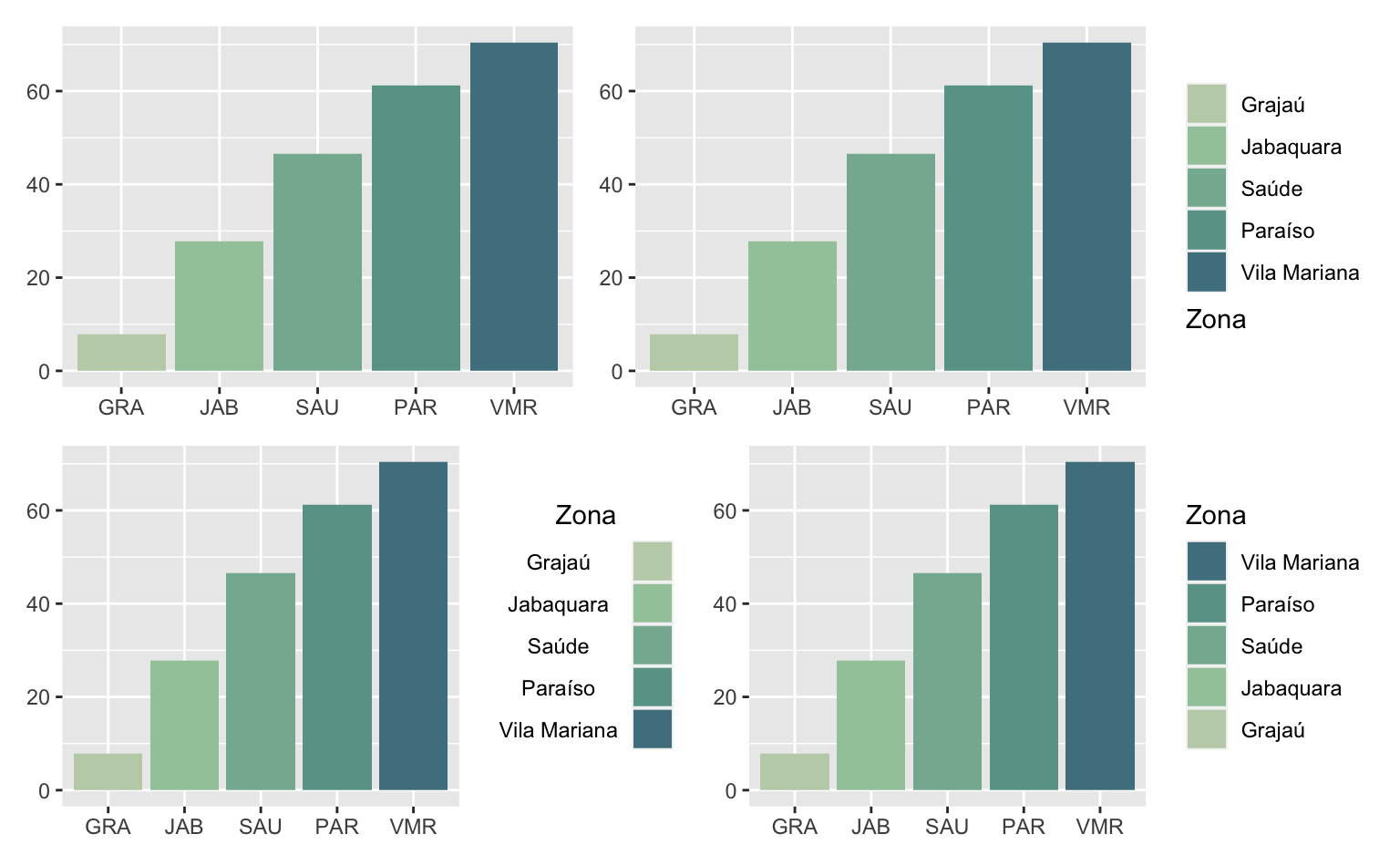
Como mencionado acima, pode-se usar funções com cores pré-definidas. Abaixo mostro alguns exemplos.
base_plot <- ggplot(subpod, aes(x = name_zone, y = prop_educ_superior)) +
geom_col(aes(fill = name_zone)) +
labs(x = NULL, y = NULL) +
scale_x_discrete(labels = c("GRA", "JAB", "SAU", "PAR", "VMR"))
#> Usando ColorBrewer
base_plot + scale_fill_brewer(type = "qual", palette = 4)
#> Escala de cinza
base_plot + scale_fill_grey()
#> Usando Ghibli, cores do filme Princesa Mononoke
base_plot + ghibli::scale_fill_ghibli_d("MononokeMedium")
#> Usando MetBrewer, cores do artista Hokusai
base_plot + MetBrewer::scale_fill_met_d("Hokusai1")
Por fim, mostro um exemplo onde as cores podem tanto ajudar a enxergar tendências de longo prazo como também algum tipo de padrão sazonal nos dados. O gráfico de linha abaixo mostra o preço mediano de venda de imóveis na cidade de Austin a cada mês durante o período 2000-2014.
Repare no uso da função scale_x_continuous para mostrar o nome abreviado de cada mês no eixo-x e o uso de as.factor para garantir que o R interprete a variável year como categórica e não como contínua.
austin <- filter(txhousing, city == "Austin", year < 2015)
ggplot(austin, aes(x = month, y = median)) +
geom_line(aes(color = as.factor(year))) +
scale_x_continuous(breaks = 1:12, labels = month.abb) +
scale_color_viridis_d()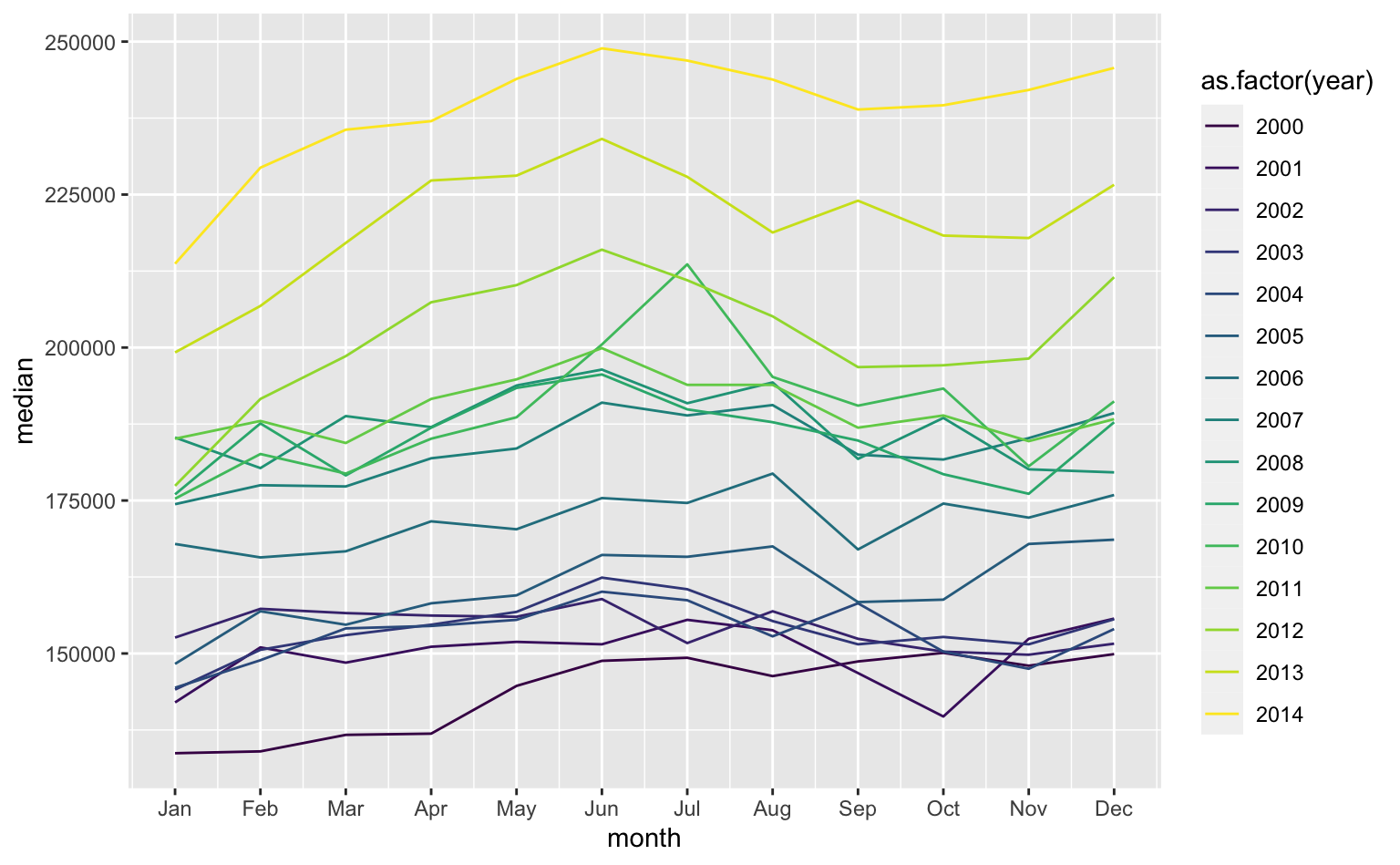
Variáveis contínuas
A mesma lógica apresentada acima se aplica a variáveis contínuas. Infelizmente, algumas das aplicações mais úteis de escalas de cores contínuas envolvem tipos de gráficos que ainda não vimos, como geom_tile() e geom_sf().
O exemplo abaixo mostra a relação entre renda e escolaridade, olhando especificamente para a taxa de indivíduos com ensino superior. Note o uso da função scale_y_log10.
A função scale_color_continuous não é particularmente útil pois, ao contrário do caso discreto, em que podíamos escolher as cores manualmente usando a função scale_color_discrete ou scale_color_manual, não existe uma maneira de “escolher” as cores no caso contínuo.
O problema acontece porque teríamos que escolher “infinitas” cores, ou melhor, todo um gradiente de cores. Para definir um gradiente de cores com facilidade, usamos a função scale_color_gradient. Esta função define um gradiente a partir dos argumentos low e high.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density)) +
scale_y_log10() +
scale_color_gradient(low = "blue", high = "orange")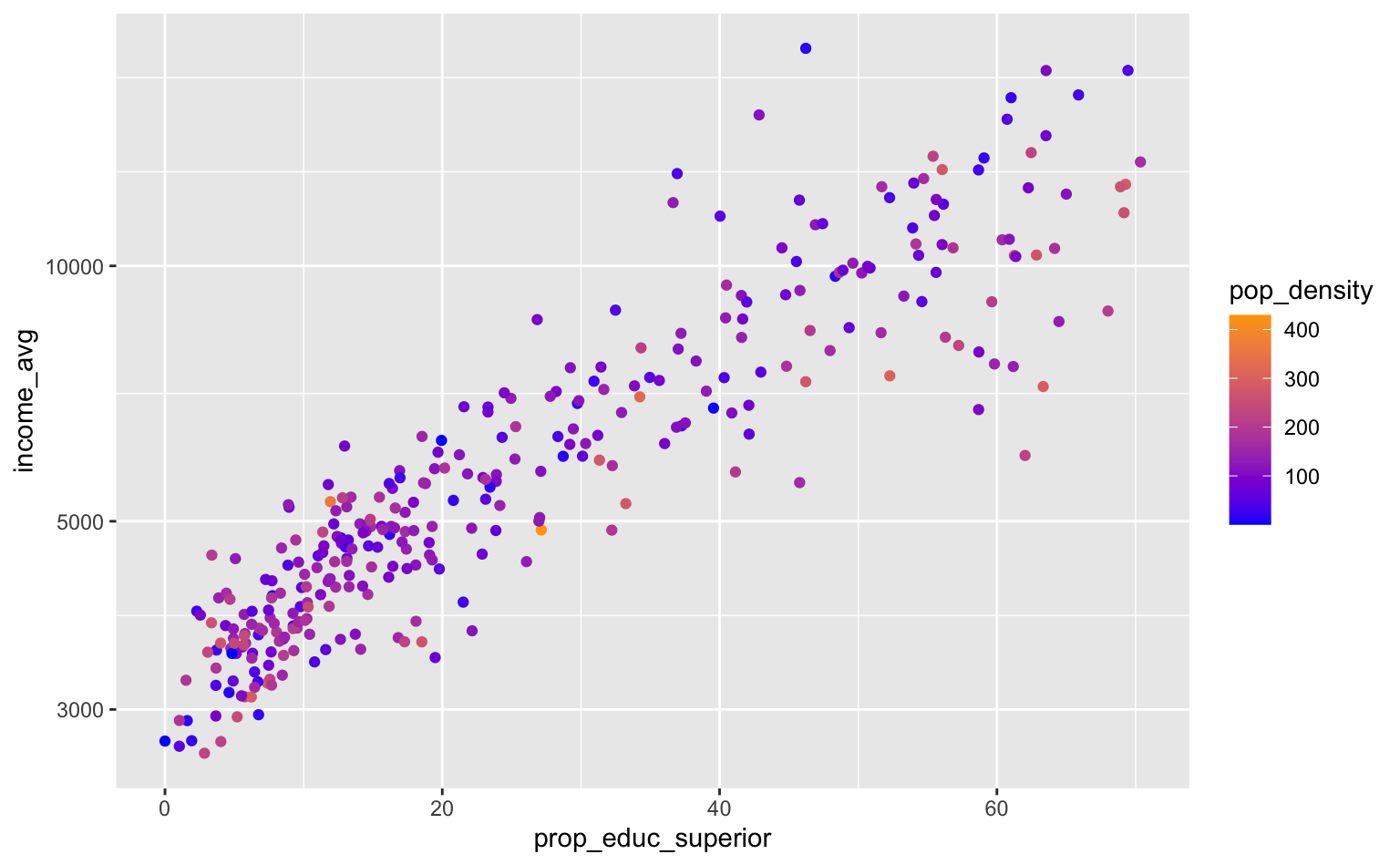
Para construir um gradiente “divergente”, que destaca valores longe da média, por exemplo, pode-se usar scale_color_gradient2. O exemplo abaixo usa a função scale para “normalizar” a densidade populacional.
O gráfico agora destaca em azul/roxo as Zonas com alta densidade populacional e em vermelho as Zonas com baixa densidade populacional; as Zonas com densidade próximas da média ficam em branco.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = scale(pop_density))) +
scale_y_log10() +
scale_color_gradient2(limits = c(-4, 4))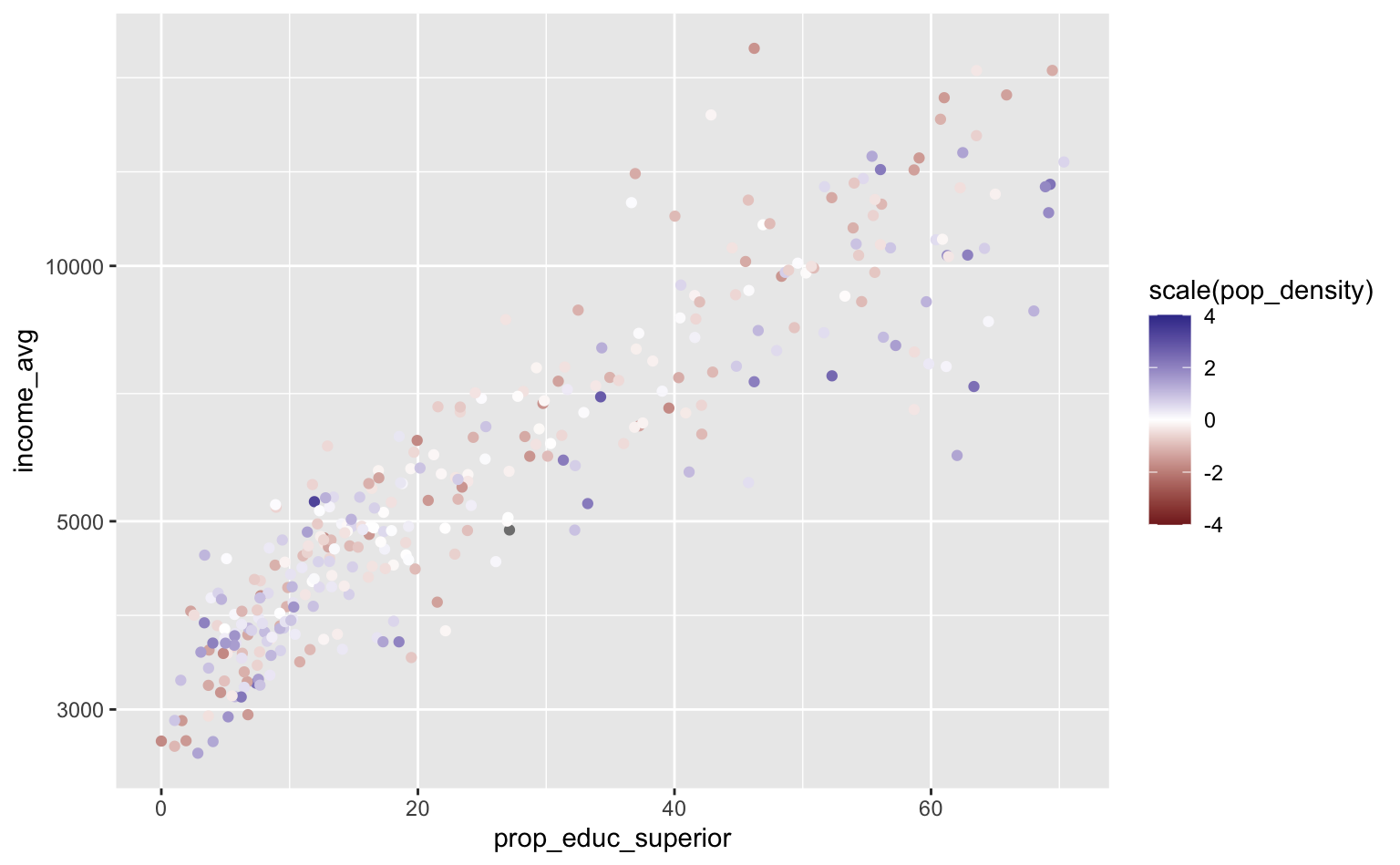
Uma função muito útil para trabalhar este tipo de dado é a scale_*_distiller(), que cria gradientes de cores a partir das paletas de cores do ColorBrewer, que vimos anteriormente. A cor de cada ponto no gráfico abaixo ilustra a densidade populacional de cada Zona em que os pontos mais escuros são as Zonas mais densas.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density)) +
scale_y_log10() +
scale_color_distiller(palette = 3, direction = 1)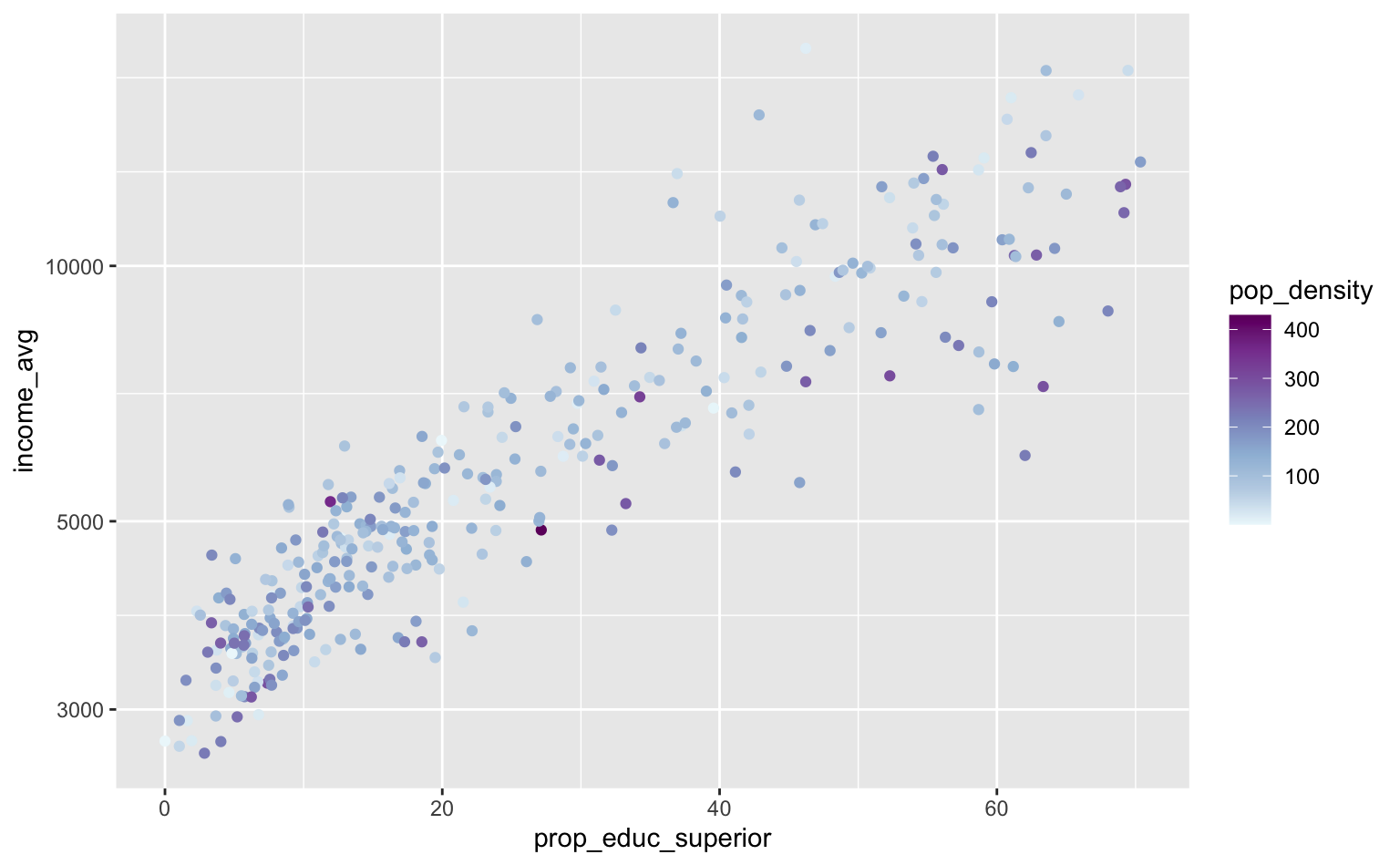
A principal vantagem de trabalhar com esta função é a facilidade em testar e gerar boas escalas de cores. Os exemplos abaixo mostram algumas das aplicações. Para conhecer mais vale consultar ?scale_color_distiller.
base_plot <- ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density)) +
scale_y_log10() +
guides(color = "none")
#> Seleciona uma paleta de cores usando número e tipo
base_plot + scale_color_distiller(palette = 1, type = "sequential")
#> Seleciona uma paleta de cores usando uma abreviação (BluesGreen)
base_plot + scale_color_distiller(palette = "BuGn")
#> Seleciona uma paleta de cores usando uma abreviação (YellowOrangeRed)
base_plot + scale_color_distiller(palette = "YlOrRd")
#> Seleciona uma paleta de cores e inverte a direção
base_plot + scale_color_distiller(palette = 1, direction = 1)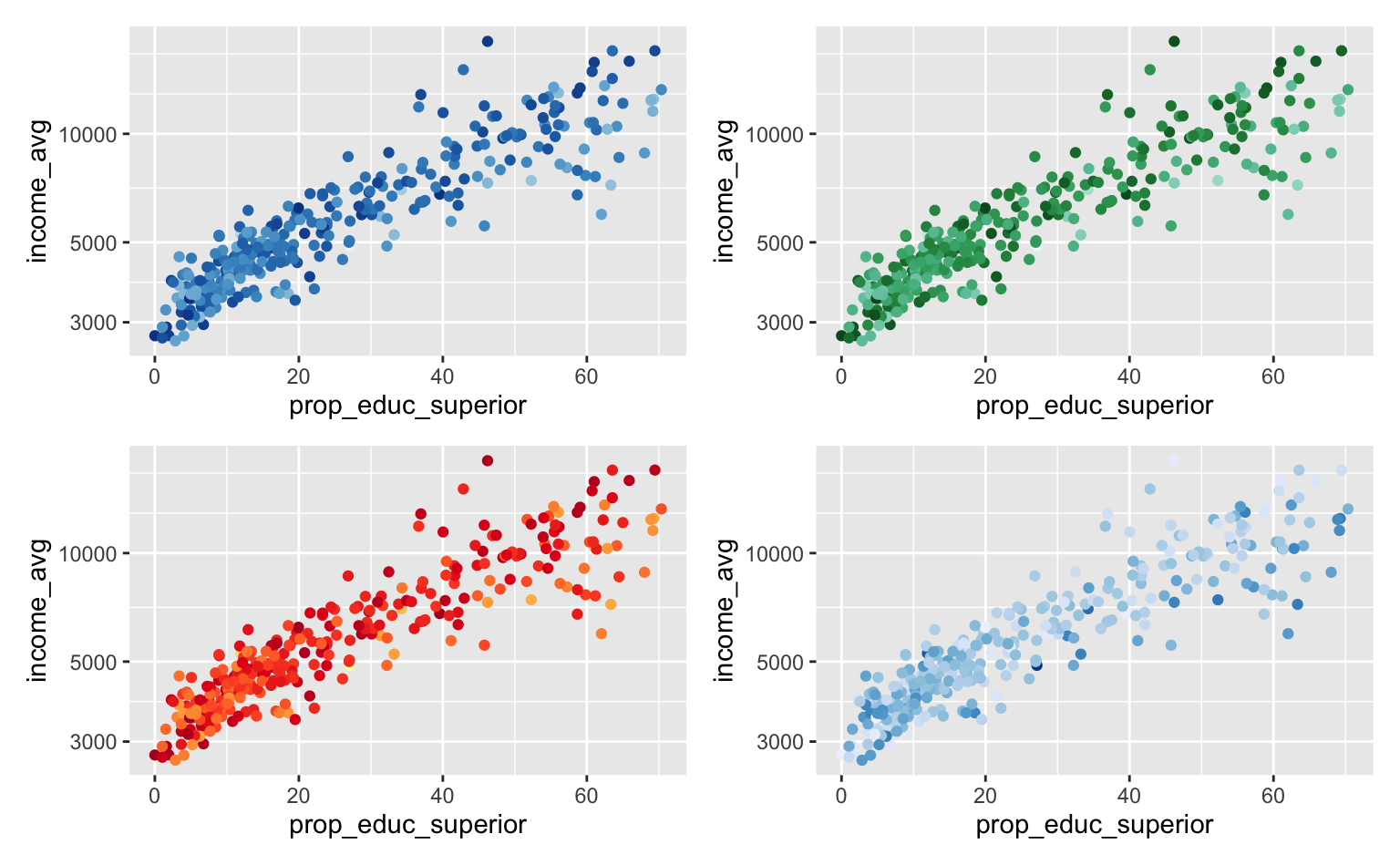
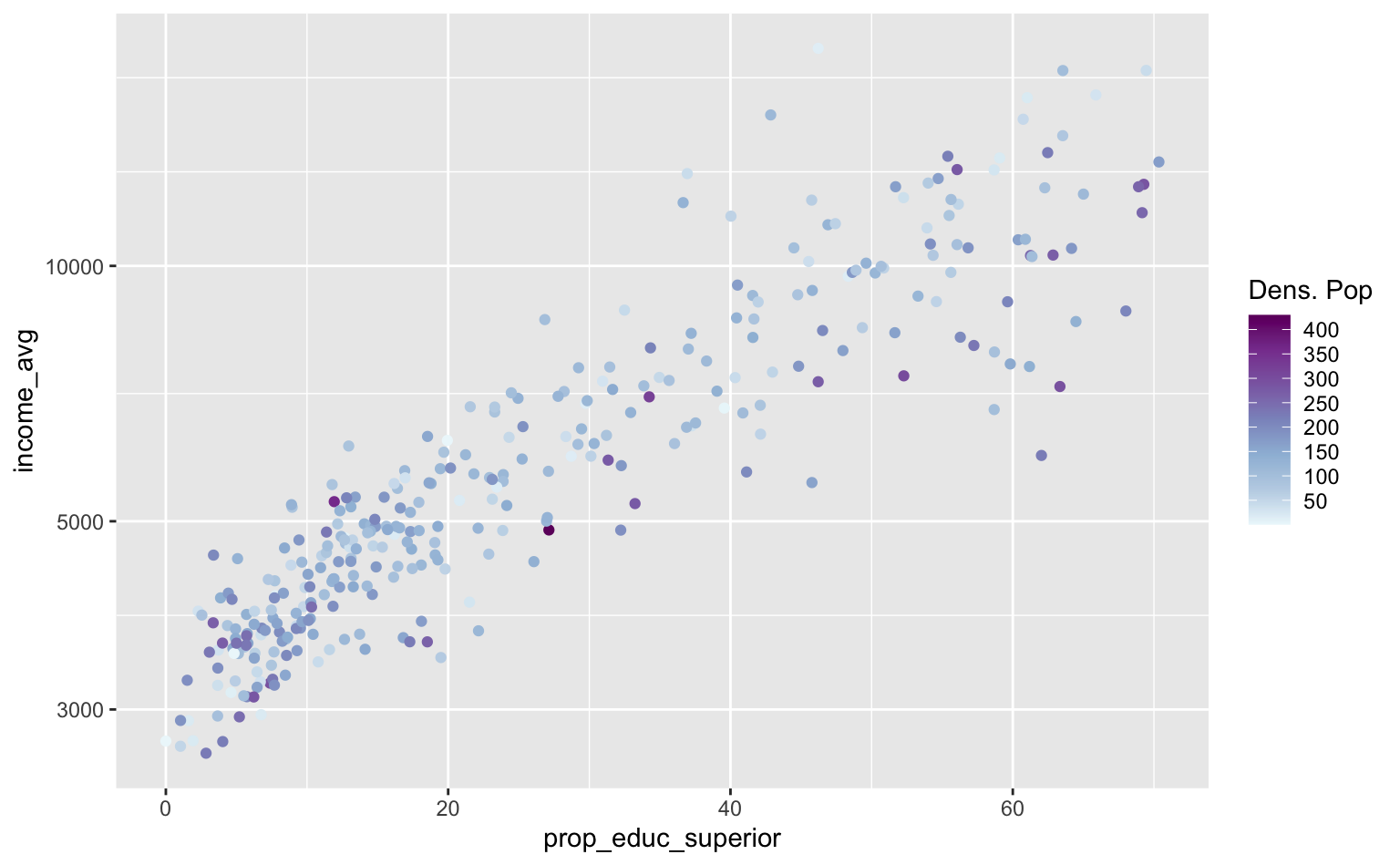
Novamente, os argumentos das funções scale_* são compartilhados. No exemplo abaixo, mostro como usar breaks dentro de scale_color_distiller.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density)) +
scale_y_log10() +
scale_color_distiller(
name = "Dens. Pop",
breaks = seq(50, 400, 50),
palette = 3,
direction = 1
)
A função scale_*_binned permite uma visualização um pouco mais simplificada de dados contínuos ao agrupar eles em grupos. Esta função não permite customizar a escolha dos grupos, mas, em geral, ela funciona muito bem. Em casos mais complexos, vale mais a pena agrupar os dados antes de visualizá-los, e então tratá-los como dados discretos. Outra opção é usar uma função que permita maior controle como scale_color_steps ou scale_color_gradient.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density), alpha = 0.7) +
scale_y_log10() +
scale_color_binned(type = "viridis")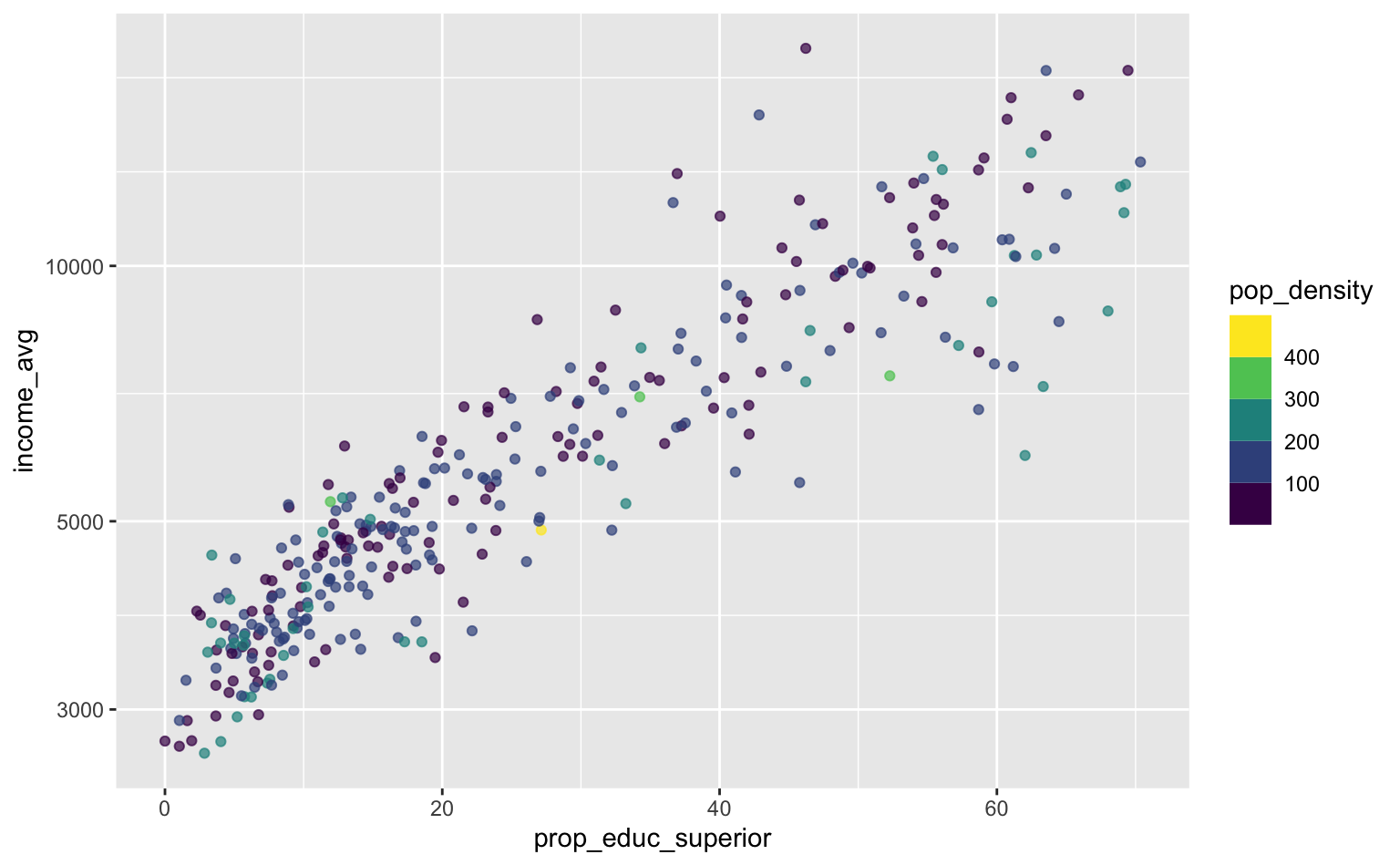
A função scale_color_binned tem apenas duas opções de cores: "gradient" e "viridis". Contudo, ela também aceita escalas customizadas de outras funções. No exemplo abaixo mostro como utilizar uma escala do MetBrewer.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density), alpha = 0.7) +
scale_y_log10() +
scale_color_binned(type = \(x) MetBrewer::scale_color_met_c(name = "VanGogh3"))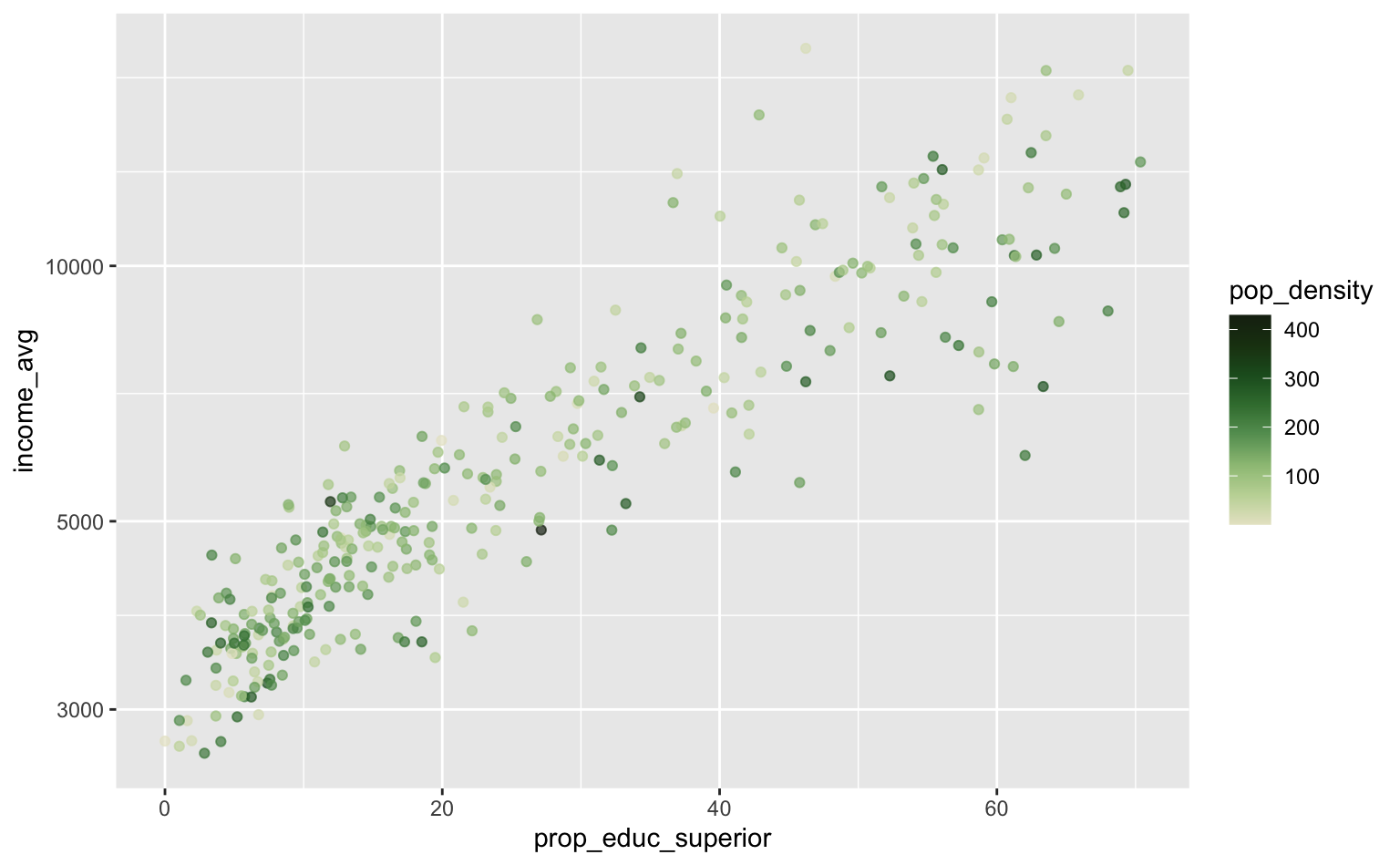
Por fim, para controlar os detalhes da legenda, novamente usa-se a função guides mas agora em conjunto com guide_colorbar.
ggplot(pod, aes(x = prop_educ_superior, y = income_avg)) +
geom_point(aes(color = pop_density), alpha = 0.7) +
scale_y_log10() +
scale_color_binned(type = "viridis") +
guides(color = guide_colorbar(reverse = TRUE))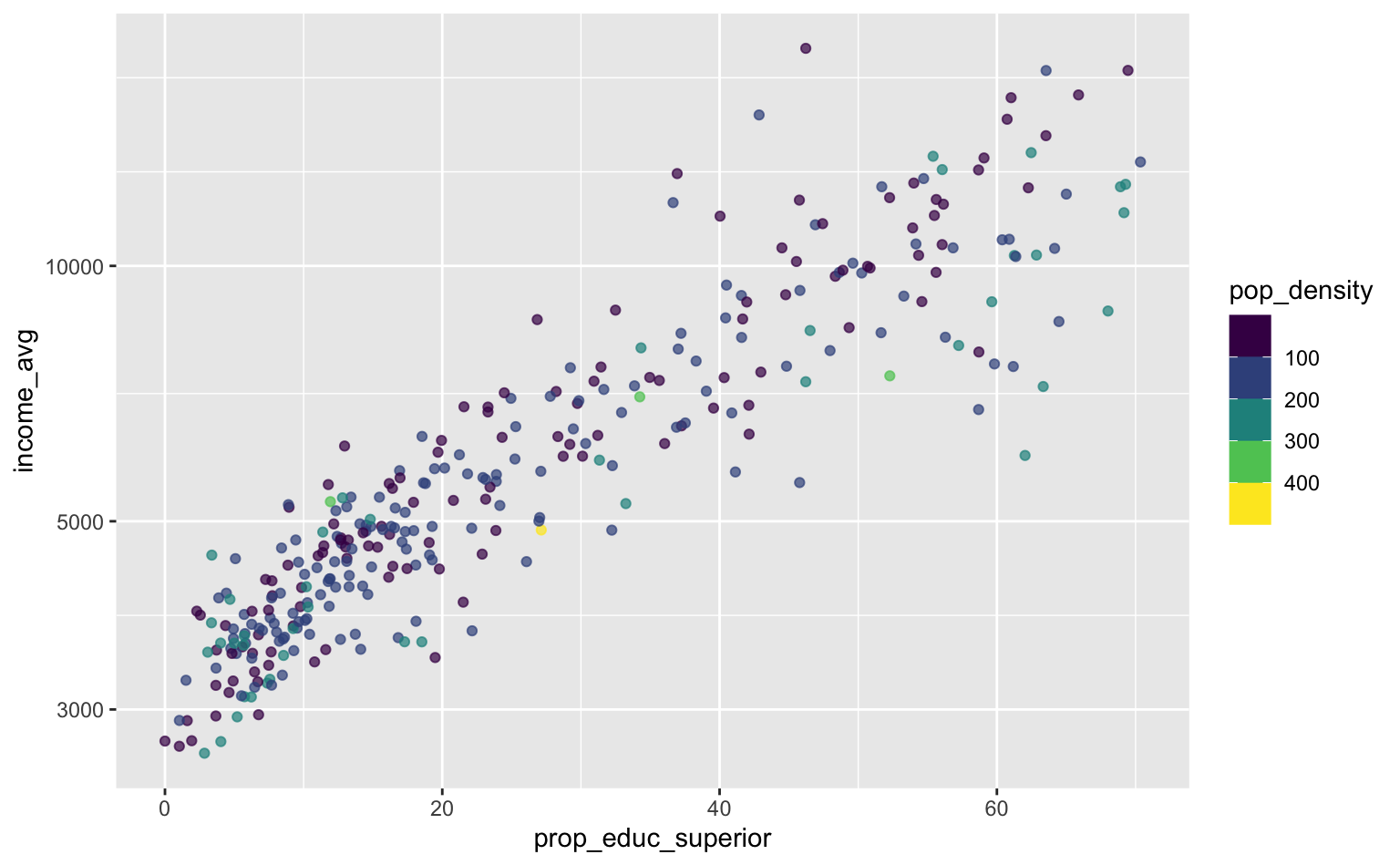
O {ggplot2} é um pacote muito flexível, oferece todo tipo de visualização imaginável. Como resultado, podemos (como já vimos em vários casos) gerar todo tipo de gráfico sem sentido. O exemplo abaixo mostra novamente a série da taxa de poupança, mas agora a cor da linha é proporcional à taxa de desemprego naquele mês.
ggplot(economics, aes(x = date, y = psavert)) +
geom_line(aes(color = unemploy/pop)) +
scale_color_viridis_c()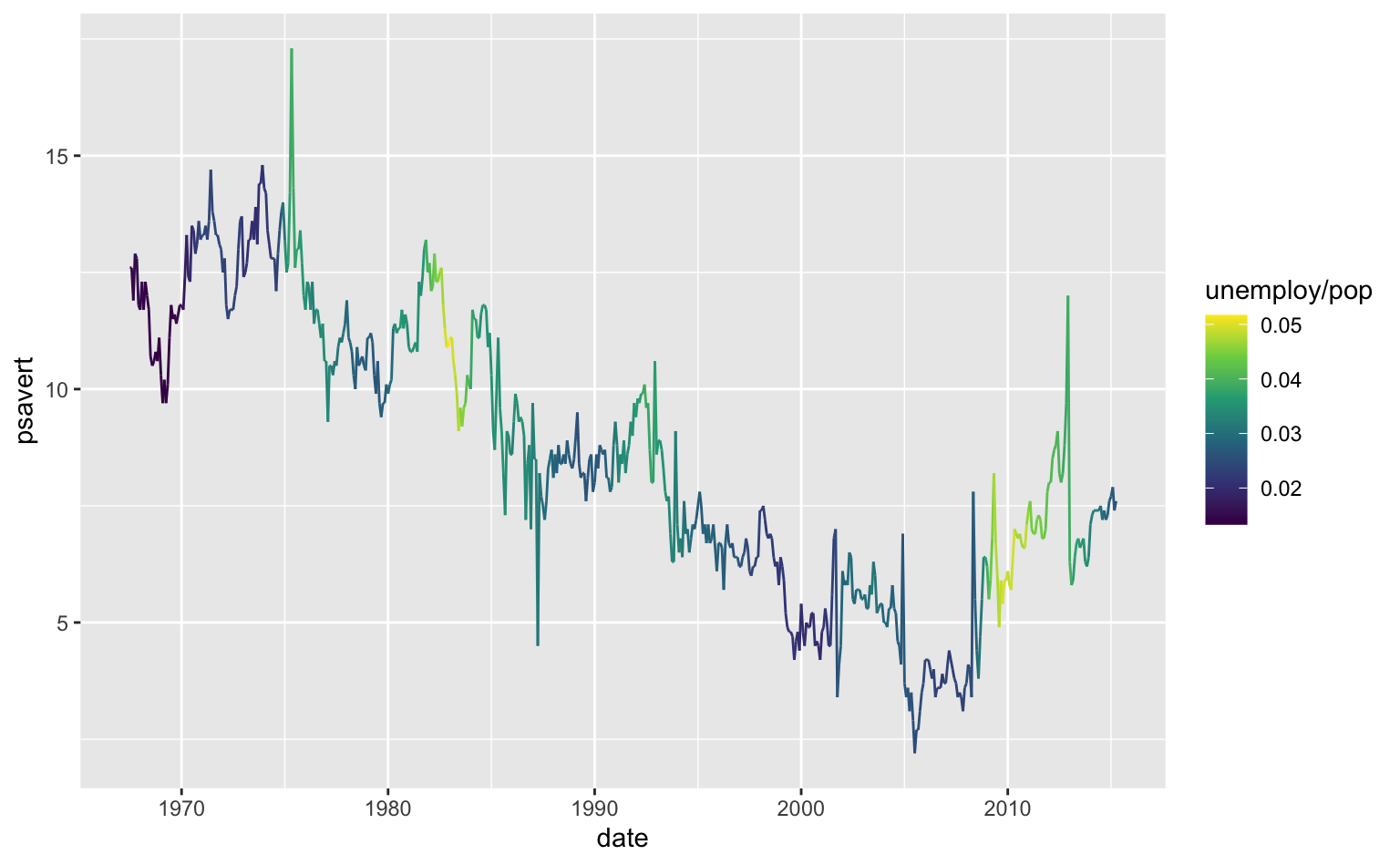
Em geral, usa-se cores em gráficos de linha para ajudar a distinguir entre diferentes séries de tempo. Pode-se usar cores diferentes numa única série para enfatizar a sua mudança no tempo. O gráfico abaixo mostra a série das “anomalias de temperatura” nas últimos décadas. Por anomalia de temperatura, entende-se, o desvio da temperatura média anual em relação à média histórica (1951-1980)4.
gtemp_both <- astsa::gtemp_both
# Converte o objeto para data.frame
df <- data.frame(
date = as.numeric(time(gtemp_both)),
temp = as.numeric(gtemp_both)
)
ggplot(df, aes(x = date, y = temp, color = temp)) +
geom_line() +
scale_color_viridis_c(option = "inferno")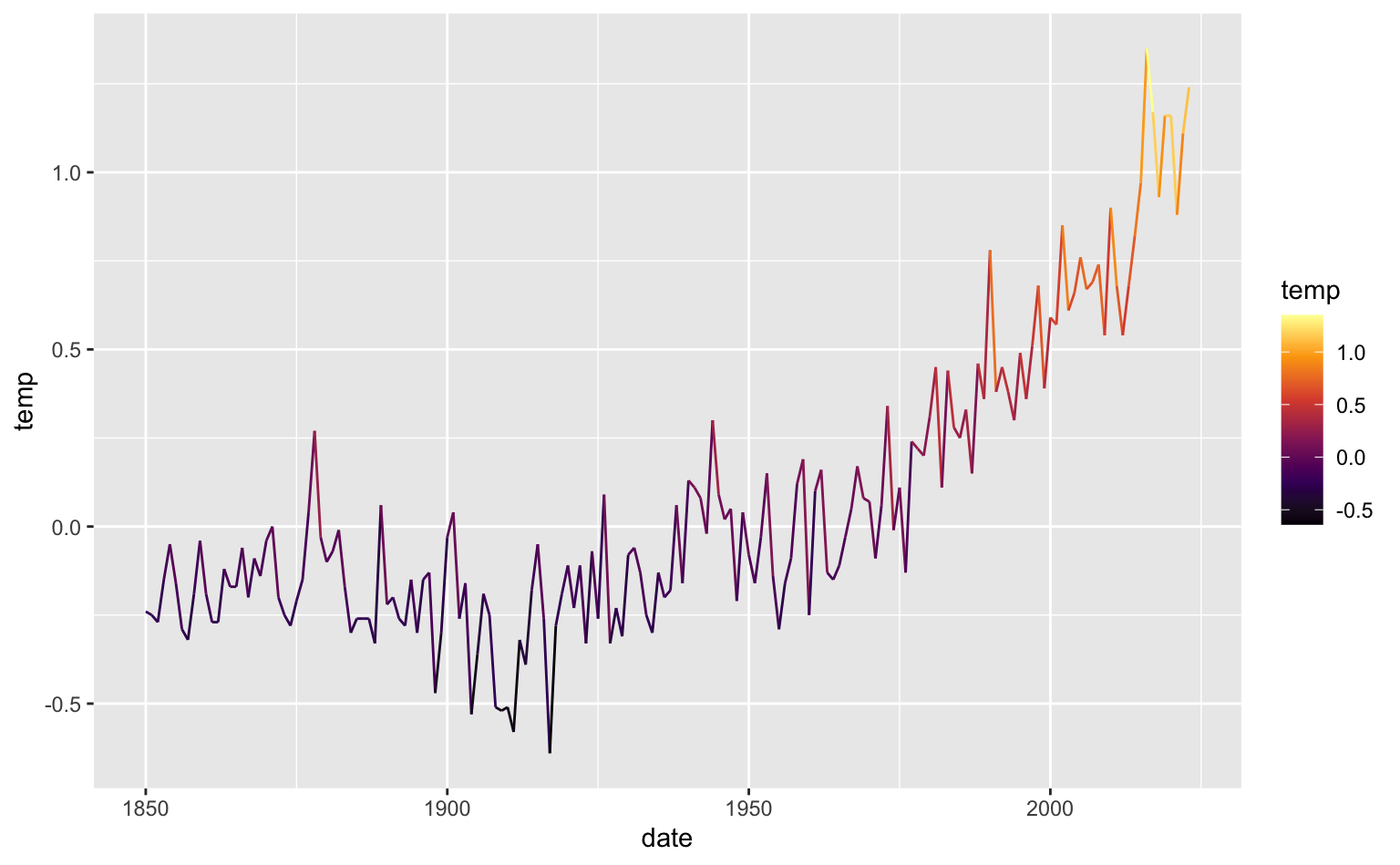
Outros elementos estéticos
Para efeitos de {ggplot2} o tamanho e a transparência dos objetos também são elementos estéticos. O exemplo abaixo mostra como controlar a legenda no caso em que o tamanho do elemento é variável. Nos gráficos abaixo, mostro o mesmo gráfico de renda e carros, mas agora o tamanho de cada ponto é proporcional à população total de cada Zona. Eu omito a legenda usando guides(size = "none").
base_plot <- ggplot(pod, aes(x = income_avg, y = car_rate)) +
geom_point(aes(size = pop), alpha = 0.5) +
guides(size = "none")
p1 <- base_plot + scale_size_continuous(range = c(0, 5))
p2 <- base_plot + scale_size_continuous(range = c(0, 8))
p3 <- base_plot + scale_size_continuous(range = c(0, 10))
p4 <- base_plot + scale_size_continuous(range = c(0, 20))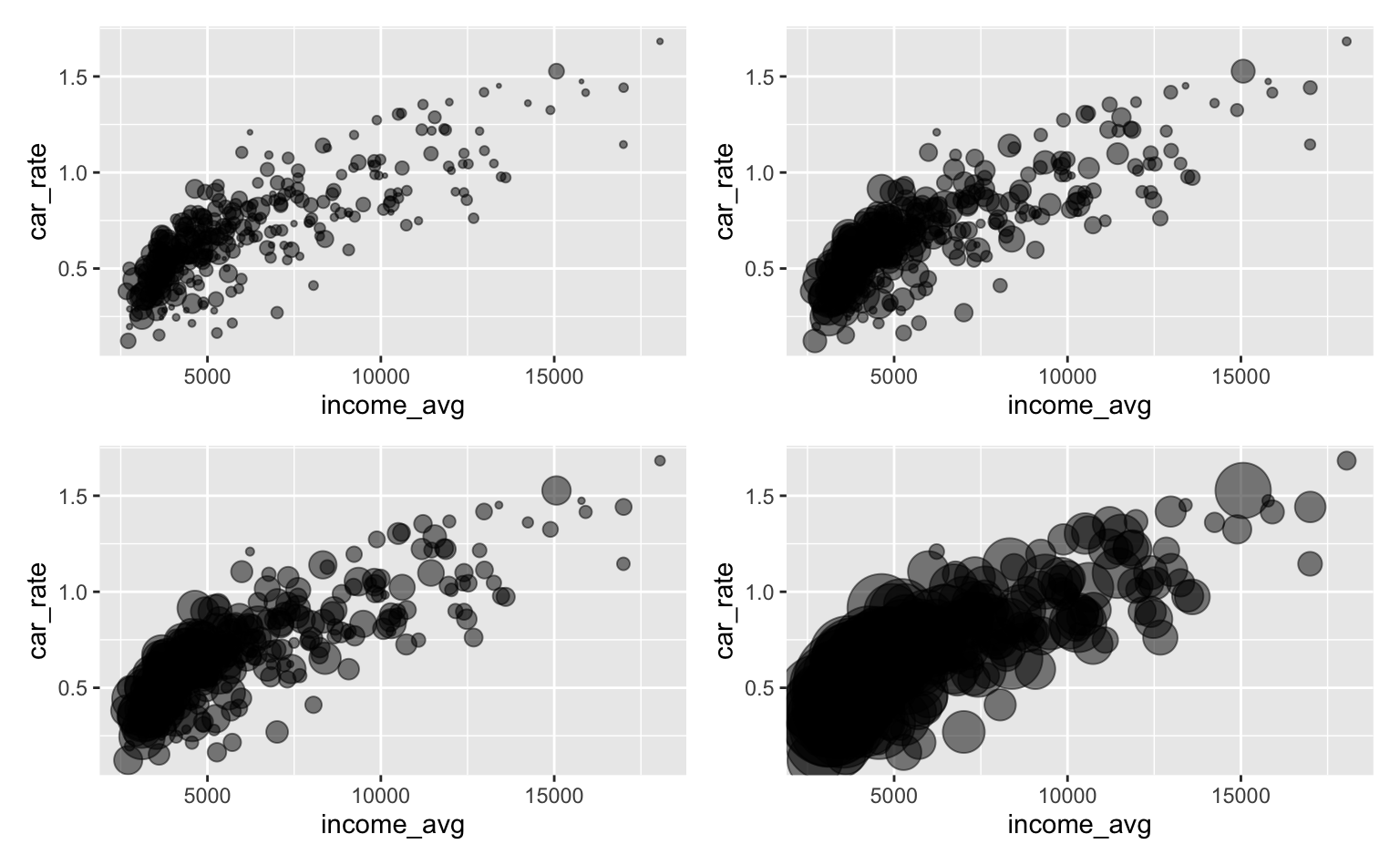
Outro elemento estético comumente utilizado é alpha, que controla a transparência da visualização. Honestamente, apesar dele ser muito útil para evitar a sobreposição de elementos no gráfico, é difícil imaginar algum uso prático de scale_alpha. O gráfico abaixo mostra o estoque de imóveis e o preço mediano de venda por mês.
txhousing |>
filter(city == "Austin") |>
ggplot(aes(x = inventory, y = median)) +
geom_point(aes(alpha = year)) +
scale_alpha()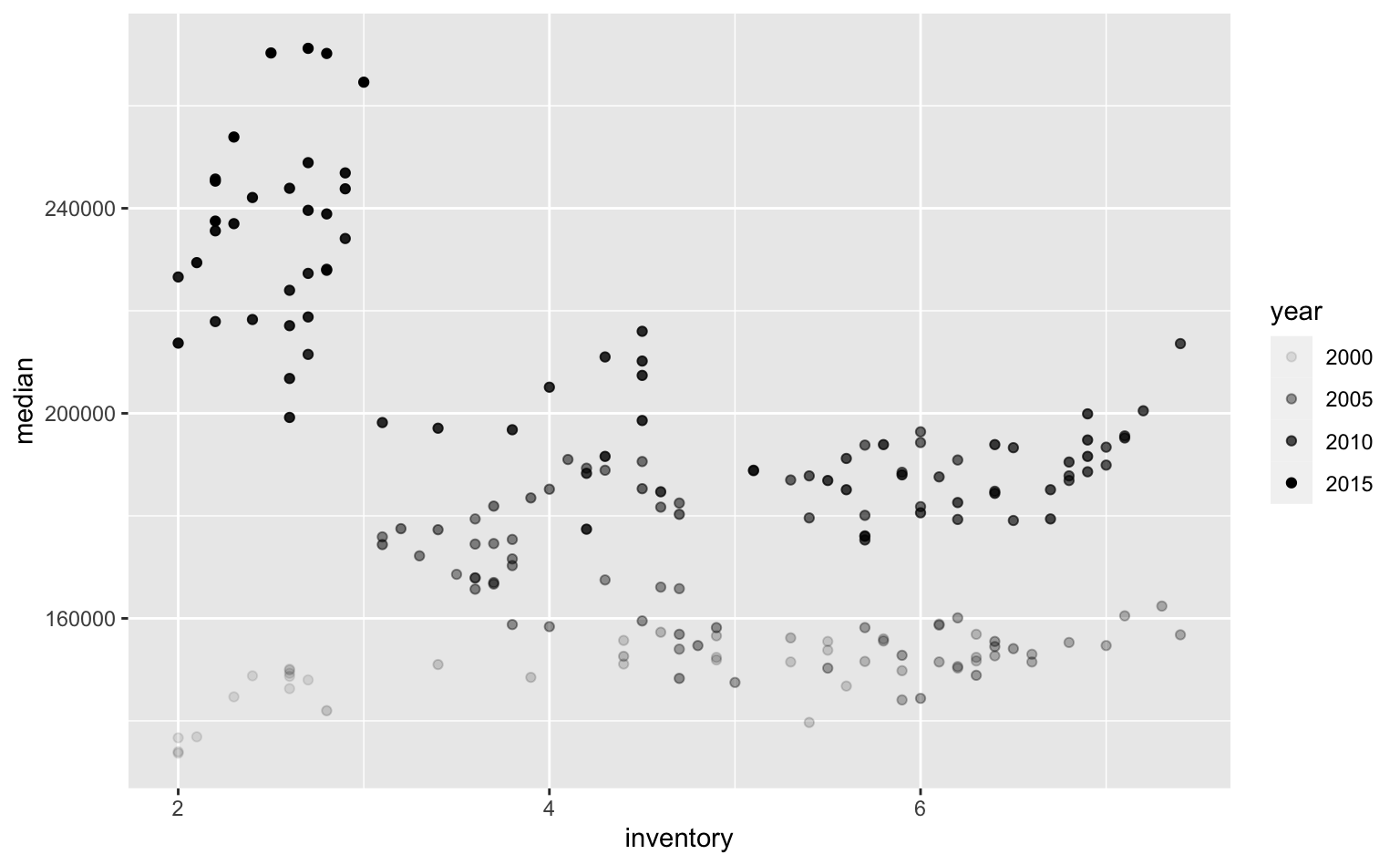
Resumo
Este foi o post mais longo e mais técnico da série de tutoriais até o momento. Por algum tempo pensei em separar ele em duas partes, mas acredito que há vantagens em apresentar cores e escalas conjuntamente, já que as funções compartilham sintaxes semelhantes. A discussão inevitavelmente torna-se mais técnica pois agora é preciso pensar no formato das variáveis (Date, factor, etc.). Isto, contudo, é um ponto positivo pois força o usuário a pensar melhor nas suas variáveis e recompensa o uso de bases de dados limpas e organizadas.
Escalas, legendas e cores são elementos essenciais numa boa visualização. Às vezes elas podem exigir um trabalho considerável, mas este esforço muitas vezes diferencia uma visualização simplória de uma visualização refinada.
Footnotes
Vale lembrar, que a cidade de São Paulo não possui uma divisão oficial de bairros, apenas de distritos e subprefeituras.↩︎
Existe também a função
scale_y_datemas datas quase sempre são apresentadas no eixo-x.↩︎Não conheço boas referências sobre teoria de cores em português. Atualmente, o ChatGPT pode fornecer boas paletas de cores: “Quero uma paleta de cores profissional com tons de laranja. Esta paleta de cores será utilizada dentro do R. Quero o retorno em vetores de tamanhos de 3 a 8 elementos com cores em formato hexadecimal. Retorne os vetores numa lista.”.↩︎
Esta base de dados é exportada em conjunto com o pacote
astsa. Para mais informações consulte o site da NASA, que é a fonte original dos dados e que, também, disponibiliza uma versão atualizada da série.↩︎